几个定义
性能测试(Performance Test)
通常收集所有和测试有关的所有性能,通常被不同人在不同场合下进行使用。测试软件在系统中的运行性能,度量系统与预定义目标的差距。
关注点:how much和how fast
负载测试(Load Test)
负载测试是一种性能测试,指数据在超负荷环境中运行,程序是否能够承担。通过逐步增加系统负载,确定在满足性能指标的情况下,系统所能承受的最大负载量。
关注点:how much
压力测试(Stress Test)
压力测试是一种高负载下的负载测试,也就是说被系统处于一个负载的情况,再继续对他进行加压,形成双重负载,知道系统崩溃,并关注崩溃后系统的恢复能力,以前再加压的一个过程,看看系统到底是否已经被彻底破坏掉了。
有个很形象的说法就是:你能够承担100千克的重量,而且也能走,但是你能否承担100千克的重量行走1个月。
外部的负载叫压力,内部的压力叫负载。负载注重关注内部的以及系统自身一些情况;而压力更关注系统外部的表象.
性能测试模型
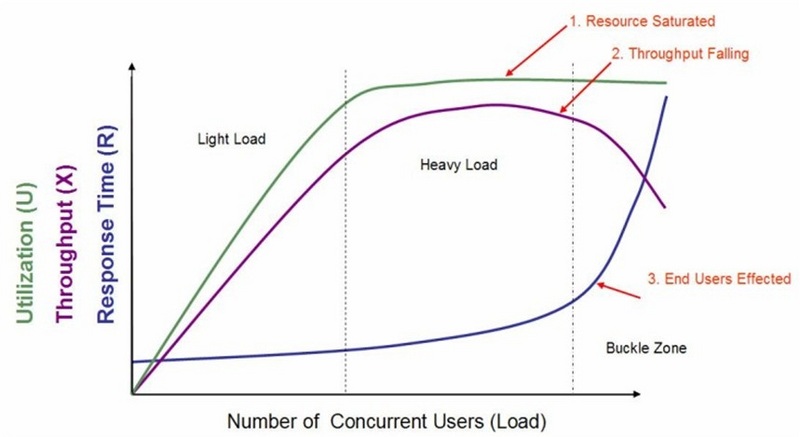
性能测试的执行过程是由轻到重,逐渐对系统施压。通常用户最关心的性能指标包括:响应时间、吞吐量、资源利用率和最大用户数。我们可以将这张图分成3个区域,即:轻负载区域、重负载区域和负载失效区域。
· 轻负载区域
在这个区域您可以看到随着虚拟用户数量的增加,系统资源利用率和吞吐量也随之增加,而响应时间没有特别明显的变化;
· 重负载区域
在这个区域您可以发现随着虚拟用户数量的增加,系统资源利用率随之缓慢增加,吞吐量开始也缓慢增加,随着虚拟用户数量的增长,资源利用率保持相对的稳定(满足系统资源利用率指标),吞吐量也基本保持平稳,后续则略有降低,但幅度不大,响应时间会有相对较大幅度的增长;
· 负载失效区域
在这个区域系统资源利用率随之增加并达到饱和,如CPU利用率达到95%甚至100%,并长时间保持该状态,而吞吐量急剧下降和响应时间大幅度增长(即:出现拐点)。
· 两个交界点
在轻负载区域和重负载区域交界处的用户数,我们称为"最佳用户数"。而重负载区域和负载失效区域交界处的用户数则称为"最大用户数"。
当系统的负载等于最佳用户数时,系统的整体效率最高,系统资源利用率适中,用户请求能够得到快速响应;
当系统负载处于最佳用户数和最大用户数之间时,系统可以继续工作,但是响应时间开始变长,系统资源利用率较高,并持续保持该状态,如果负载一直持续,将最终会导致少量用户无法忍受而放弃;
而当系统负载大于最大用户数时,将会导致较多用户因无法忍受超长的等待而放弃使用系统,有时甚至会出现系统崩溃,而无法响应用户请求的情况发生。
并发用户数
相对并发用户数(用户视角)
即线用户数,在一个时间段内,与服务器进行了交互、对服务器产生了压力的用户的数量。这个时间段,可以是一天,也可以是一个小时。
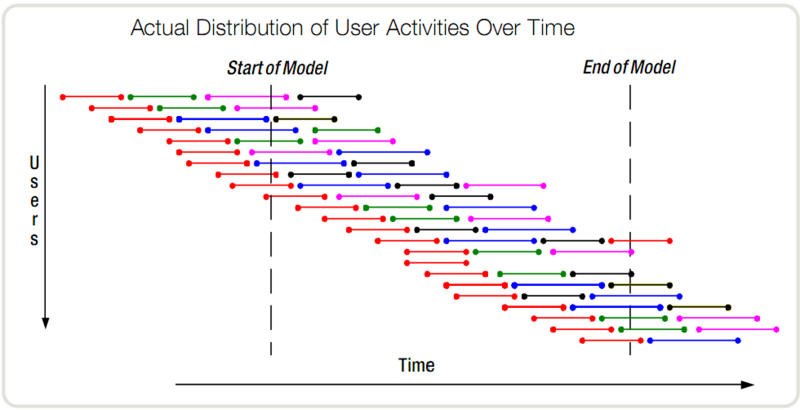
通常像ab、wrk等并发工具设定的并发数,就是指的这个并发数,比如在JMeter中,如果将某个线程组的线程数设置为100,那是不是对于这个类型的请求,并发量就是100。从宏观的角度,这样理解也是对的,就好比请了100个人,每个人独立地完成一连串的工作,确实是100个在并行。但是对于服务器感受到的压力,可能就不是100了。
这里所谓的100个并行对于服务端而言并不是严格的全部并行,因为每个虚拟用户执行的节奏是独立。假设这个操作需要3个请求完成,那么很有可能出现这样的情况:某个虚拟用户还在等待第一个请求的响应,但是另一个虚拟用户已经收到了第一个请求的响应并发起了第二个请求。那么对于服务端而言,在某一个时刻,无论是对于请求1还是请求2,并行度都没有到100。这个模型比较类似于图中右边部分所示的模型。理解这个模型对于并行的理解非常重要。
这里的差异在于宏观上的并行还是严格意义上的并行,比如就某个请求的严格意义上的并行或许可以通过TCP连接的保持数来看。通过“netstat|grep ESTABLISH|wc-l”命令获得保持连接状态的TCP请求数量。也就是下面的绝对并发用户数。
并发与并行是相关的概念,但是也有很多细节上的差异。并发意味着两个或更多的任务正在取得进展,即使它们不是同时执行的。例如,可以用时间片的方式实现这一点,每个任务在时间片内执行一小部分,并与其它任务的切片混合执行。如并发收集器。并行的出现使任务实现了真正的同时执行。
绝对并发用户数(服务器视角)
主要是针对某一个操作进行测试,即多个用户同一时刻发起相同请求。
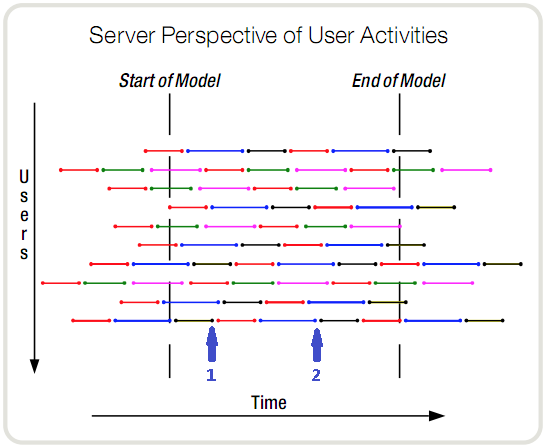
图中,每一个颜色的线段代表一种操作。在任意一个时刻,服务器都知道它有10个事务需要处理,这10个事务也是有10个用户产生的。但它不知道的是,整个时间段内的所有事务,是由多少个用户与系统交互而产生的。时刻1,10个当前事务是由10个用户发起的。时刻2,依然是10个正在进行的事务,但可能是完全不同的10个人发起的。在这段时间内,服务器每一个时刻都在处理10个事务,但是参与了这个交互过程(对服务器产生压力)的人可能会达到上百个,也可能只有最开始的10个。那么,对于服务器来说,压力是什么呢?显然只是每时刻这10个同时处理的事务。
Think Time
在进行相对并发用户数的测算时,think time的设置会影响测试的结果。设想这样的一个场景,一个真实的用户在某个电商网站上购物,一个简化的流程可能如下: 1)进入首页 2)搜索一个商品 3)查看商品详情 4)加入购物车 5)提交订单 6)完成支付 基于上面的讨论我们可以构造一系列JMeter请求,放在一个线程组里面。 如果我们要测试针对这样的用户,我们的系统可以支持多少人同时来购物。假设我们已经考虑了用户登录账号和购买商品的参数化问题,是否可以直接将线程组的数值设置到一个较大的数值,然后并发执行呢?
这样可以执行起来,但是有一个很大的问题。在于真实用户和脚本的不同。脚本如果是基于前面方法录制的,两个请求的执行时间之前是没有任何其他停顿的,其间隔只是依赖于上一个服务的响应时间和测试机发起请求所需的时间。但是显然真实的用户不是机器,他们在做上面每一个步骤的时候都有一个思考的时间,这也是Think Time这个词的意义来源。
当然,这个思考时间也是泛指,包括了用户操作的时间,比如进入首页后,用户需要在搜索框中输入想购买商品的关键词,打开输入法并输入相关的词可能也需要少则几秒钟的时间,搜索结果出来之后用户需要浏览和选择,找到感兴趣的商品并点击查看详情,后面的步骤也是类似。 试想一下,对比请求连续执行和每个步骤间加入模拟真实用户的Think Time之后,对于同一个系统,能支持的同时在线购物人数必定会有绝大的差异,而有Think Time的做法显然更接近真实情况。
准备工作
不同的机器、操作系统、web服务器以及相关参数等的不同,也会影响性能测试的结果。有必要在测试前对参数进行一下配置。
参考做一个正确的性能测试以及高负载系统,网络参数调整进行调优。这里列一下操作系统的几个重要参数。
fs.file-max = 999999
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.ip_local_port_range = 1024 61000
net.ipv4.tcp_rmem = 4096 32768 262142
net.ipv4.tcp_wmem = 4096 32768 262142
net.core.netdev_max_backlog = 8096
net.core.rmem_default = 262144
net.core.wmem_default = 262144
net.core.rmem_max = 2097152
net.core.wmem_max = 2097152
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn.backlog=1024
· file-max:这个参数表示进程(比如一个worker进程)可以同时打开的最大句柄数,这个参数直接限制最大并发连接数,需根据实际情况配置。
· tcp_tw_reuse:这个参数设置为1,表示允许将TIME-WAIT状态的socket重新用于新的TCP连接,这对于服务器来说很有意义,因为服务器上总会有大量TIME-WAIT状态的连接。 - tcp_keepalive_time:这个参数表示当keepalive启用时,TCP发送keepalive消息的频度。默认是2小时,若将其设置得小一些,可以更快地清理无效的连接。
· tcp_fin_timeout:这个参数表示当服务器主动关闭连接时,socket保持在FIN-WAIT-2状态的最大时间。
· tcp_max_tw_buckets:这个参数表示操作系统允许TIME_WAIT套接字数量的最大值,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。该参数默认为180000,过多的TIME_WAIT套接字会使Web服务器变慢。
· tcp_max_syn_backlog:这个参数表示TCP三次握手建立阶段接收SYN请求队列的最大长度,默认为1024,将其设置得大一些可以使出现Nginx繁忙来不及accept新连接的情况时,Linux不至于丢失客户端发起的连接请求。
· ip_local_port_range:这个参数定义了在UDP和TCP连接中本地(不包括连接的远端)端口的取值范围。
· net.ipv4.tcp_rmem:这个参数定义了TCP接收缓存(用于TCP接收滑动窗口)的最小值、默认值、最大值。
· net.ipv4.tcp_wmem:这个参数定义了TCP发送缓存(用于TCP发送滑动窗口)的最小值、默认值、最大值。
· netdev_max_backlog:当网卡接收数据包的速度大于内核处理的速度时,会有一个队列保存这些数据包。这个参数表示该队列的最大值。
· rmem_default:这个参数表示内核套接字接收缓存区默认的大小。
· wmem_default:这个参数表示内核套接字发送缓存区默认的大小。
· rmem_max:这个参数表示内核套接字接收缓存区的最大大小。
· wmem_max:这个参数表示内核套接字发送缓存区的最大大小。
· tcp_syncookies:该参数与性能无关,用于解决TCP的SYN攻击。
测试工具
性能测试工具的几个核心的模块
· 压力生成器(Virtual User Generator)
· 结果采集器(Result Collector)
· 负载控制器(Controller)
· 系统资源监控器(Monitor)
· 结果分析器(Analysis)
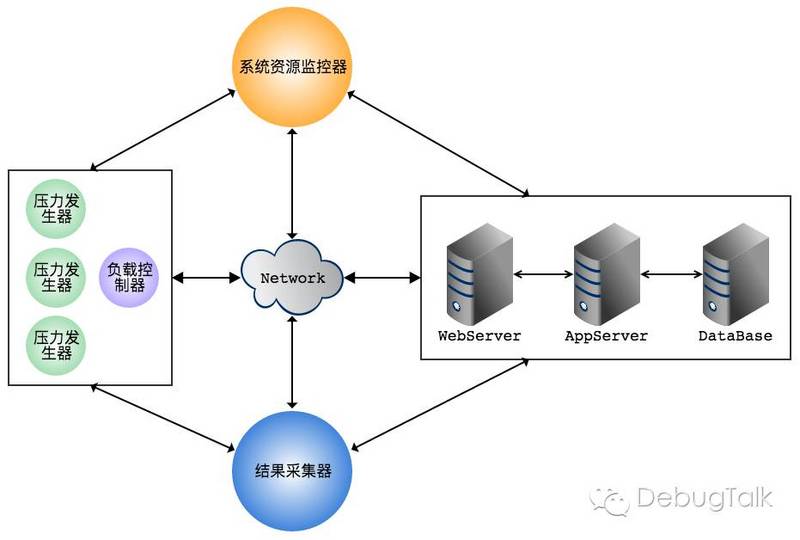
由此可以看出,像wrk、apache bench这类的工具,其实不算是完整的性能测试工具,因为它们并没有系统资源监控器,这样的话,其实简单测试出来的结果并不是很准确,只能说是简单粗暴凑合着用。
被测系统资源监控
性能测试数据收集中很重要的一部分是被测系统的资源使用情况,因为系统性能和资源使用是密切相关的,主要的目的有下面几个方面: 了解在当前压力下,系统各项资源的使用情况,也可以用于横向对比。 通过资源使用情况的分析可以看出当前是否测出了系统最大的性能。 是否有某项资源的使用已经到达上限,成为瓶颈。 是否有其他非被测系统的模块占用了资源。 通常在性能测试中,测试人员都会去收集CPU、内存、网络等服务器资源使用情况,但是如果只是笼统地给出一个百分比是不够的,需要进一步细分来提供更多有参考价值的数据。
因此如果只是简单地用wrk这类测试,记得关注被测试系统的cpu、io(网络/文件)、内存等使用情况。对于互联网的应用,特别要关注网络连接数。
系统资源瓶颈
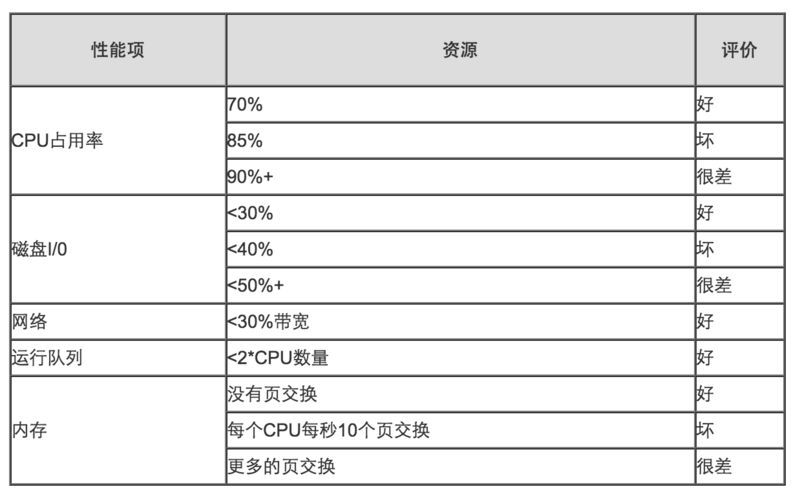
· 稳定系统资源状态
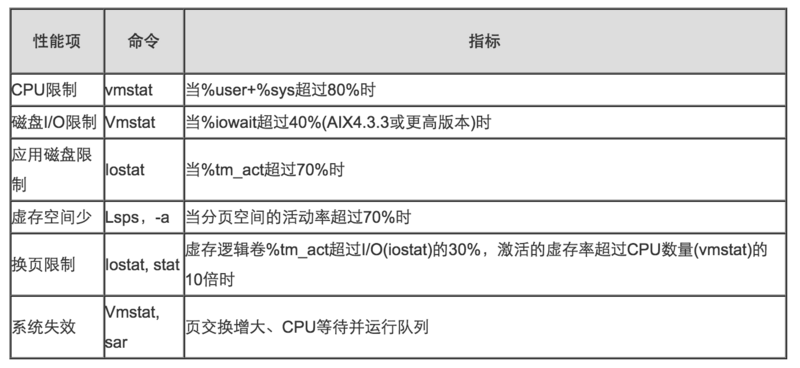
· 系统资源瓶颈
峰值流量估算
可根据历史日均压力、日最高压力等信息,估算出未来几年的日均以及日最高压力。再通过一些通用估算方法、如二八原则(80%的工作在20%时间内完成,相当于2小时完成一天8小时的工作量),将日压力转换成峰值压力。
假设系统日均pv 8000w,一天按照4w秒算,8000w/4w=2000,平均大概2000QPS,按28原则算,峰值的qps则有2000*4=8000 QPS
