作为一名QA,在对系统进行性能测试/功能性并发处理测试时,应该经常会遇到接口响应慢、并发处理报错等问题。当你遇到这些问题时,有深究过其原因么,还是只是丢给RD去排查?
相信作为一名资深QA或正在努力变成资深QA的QA,在遇到此类问题时,至少会自己先去研究一番,尝试定位问题原因。这样做,不仅能让合作的RD对你刮目相看(取得对方更多的信任,让双方的合作更加顺畅),更重要的还是能增加个人经验的积累。
一、怎么知道SQL处理慢?
现在大部分数据库都提供了性能分析工具。例如Oracle中自带的awr工具,在报告中可展示出SQL语句处理时间从高到低的排行。而在MySQL中就要自己开启慢日志记录加以分析,我们一起来看下mysql慢查询相关操作:
我们可以通过mysql配置文件或SQL命令方式,对慢查询参数进行设置。
1. 配置文件方式:linux下mysql配置文件默认路径为/etc/my.cnf,慢查询相关的参数主要有以下三个:
slow_query_log: 慢查询开关,默认是关闭的,修改为1表示开启
slow_query_log_file: 慢查询日志存放的位置
long_query_time :查询超过多少秒才记录,默认10s
2. 命令行方式查看和修改(如下命令都需要管理员账户):
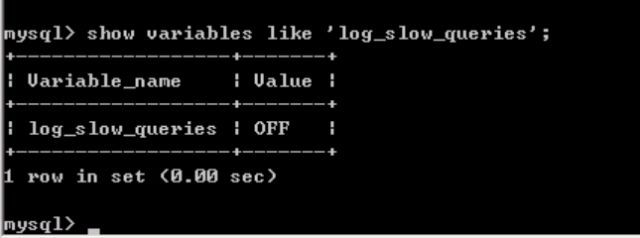
· 开启慢查询命令:set global log_slow_queries = on;
· 查看慢查询参数:show variables like ‘long_query_time’;
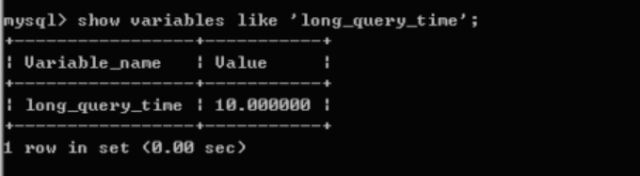
· 修改慢查询时间,即超过指定秒数就会被认为慢查询。设置命令:set global long_query_time =1;
注意:用命令设置的,会立即生效,不用重启mysql服务。但重启mysql服务后就会失效。
· 查看慢查询日志存放路径,命令: show variables like 'slow_query_log_file'
· 更改慢查询日志的存储方式,因为默认是将慢查询日志记录到文件类中的,如果你想将这些日志记录到数据库表中,使用命令:set global log_output=’TABLE’。
注意:实际应用中,出于性能考虑,一般都会保存在文件中
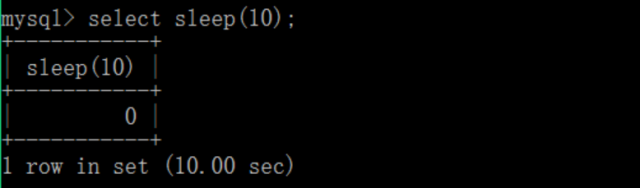
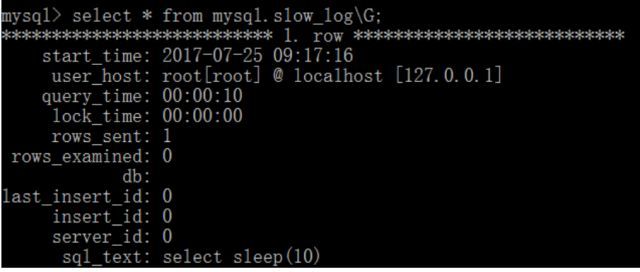
以上,我们把MySQL数据库的慢查询日志的的设置给各位简单介绍了一下。下面我们来简单模拟一下,使用MySQL数据库的sleep(N)函数来假装让执行语句停留10秒,最后我们可以到记录慢查询日志的数据表中看到这条记录。
二、找到了慢查询语句,如何优化?
通过慢查询日志监控到的SQL,并非只有SELECT语句,对数据库的CURD操作,只要超过了慢查询设置的阈值都会记录到日志中。只是在实际WEB应用中,查询操作通常能占到系统的80%以上。众所周知,正确使用索引,能大大提高查询效率,而关于MySQL索引原理是比较枯燥的东西,对于我们QA而言大家只需要有一个感性的认识,并不需要理解得非常透彻和深入。因此,如下主要从索引建立和使用方面着手进行SQL的优化探索:
首先,我们来看看建索引的一些原则(这部分对于QA来说可以只作为了解):
1. 选择唯一性索引,唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。如果使用姓名的话,可能存在同名现象,从而降低查询速度。
2. 为经常需要排序、分组和联合操作的字段建立索引,经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。如果为其建立索引,可以有效地避免排序操作。
3. 为常作为查询条件的字段建立索引,如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,为这样的字段建立索引,可以提高整个表的查询速度。
4. 限制索引的数目,索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
5. 尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
6. 尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。
此外,掌握常用的索引的使用原则,有助于QA 尽早(在程序设计或单元测试阶段)发现代码中存在的性能隐患。至少在性能测试阶段,找到慢查询语句后,通过利用这些规则进行辅助分析,可协助RD大致定位数据库性能瓶颈所在。而常用索引使用规则包括:
1. 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如:
建立(a,b,c,d)顺序的索引,a = 1 and b = 2 and c > 3 and d = 4 如果,d的索引是失效的;如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整;b=1,c=2,d=3,少了a后面的索引都是不生效的;
2. 索引列不参与计算原则,保持列“干净”,比如from_unixtime(create_time) = ’2014-05-29’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2014-05-29’);
3. 使用短索引原则,对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是唯一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
4. 索引列排序原则,MySQL查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建联合索引。
5. like语句操作,一般情况下不鼓励使用like操作,如果非使用不可,如何使用也是一个问题。like “%aaa%” 不会使用索引而like “aaa%”可以使用索引。
6. 减少or使用,要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
7. 尽量避免数据类型转换,例如:列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
8. 如果mysql估计使用全表扫描要比使用索引快,则不使用索引,这条是mysql本身的机制。
9. 尽量避免在where子句使用!= 、<>、is null判断。
三、有没有辅助工具?
有!给大家推荐一款SQL查询优化神器“explain”,为什么说是神器呢?那是因为他使用方便、功能强大。关于Explain的使用,后续文章进行介绍哦~
结束语
关于慢查询、索引、explain的每一项,网上有很多精华的资料进行介绍。在此,我仅从个人以往工作经验角度出发,把这些相关的资料给串联起来,给大家提供一个学习的思路。希望能对身为QA的你能有所帮助。
