概述
一般来说, 应用由三部分组成
· 可执行程序
· 配置
· 数据
软件系统几乎都有配置,它能灵活地定义软件的关键属性,组件之间的依赖关系与交互方式。
1. 关于配置的思考
1) 多还是少
· 为了简单,配置当然越少
· 为了灵活,配置当然越多越好
2) 自动还是手动
能自动当然不要手动,可是现实中少不了人工的参与, 对于配置属性进行添加,修改和删除
最好是一次修改, 到处可用
3) 推送还是拉取
推送与拉取取决于工作量的多少和意外情况的控制, 当服务器数量较多,分布较广,状态不一的时候,推送的方法会有问题, 不一定能推送到目标服务器上, 因为目标服务器可能并未启动,或者由于网络状态不可达, 所以拉取的方式更好一点。
当然不必每次都去配置仓库, 配置服务或配置文件里读取, 而是按需读取。 采用订阅-通知-读取是比较好的方式
4) 内部还是外部
内部宜多一点,外部宜少一点。
具体来说, 对外的, 提供给一般使用者的要尽量简单, 尽量少, 而对内的, 提供给高级管理员, 或开发者自己的配置, 可以适当多一点, 最好分个层次,不要堆积一大堆配置把人搞晕
5) 集中式还是分布式
集中式比较简单, 要注意不要有单点失败, 不支持对于跨数据中心的灾难恢复, 受网络故障的影响比较大
分布式相对复杂一点, 要注意 SSoT(Single Source of Truth), 以一处的配置数据为黄金数据, 其他各处及时同步, 要有对于网络同步不及时的应对措施
2. 配置的版本管理
所有创建软件的东西都应该纳入版本控制
· 源代码
· 测试脚本
· 数据库脚本
· 构建和部署脚本
· 文档
包括各类图表, 建议用 Markdown 和可以生成图表的脚本存储, 以利于版本之间的比较
比如 https://www.websequencediagrams.com, http://yuml.me
· 依赖的库及工具
依赖当然越少越好,可是现在的库以及工具能做的事,应用程序就能省则省
· 配置脚本及数据
3. 配置的载体
配置放哪儿呢, 最熟悉的莫过于配置文件,环境变量, 注册表或者数据库了
环境变量
这是一切和环境相关配置的首选,比如网络IP, 数据库地址,数据文件目录等
配置文件:
这是最方便, 最常用的配置载体, 配置文件的格式也是五花八门:
· ini
· properties
· json
· xml
· yaml
象 lua, python, ruby这样的脚本语言, 直接就用一个单独的脚本表示就好了
在一些特定领域,用 DSL 领域特定语言的配置更加容易理解
在实践中, 最好在读取配置文件之后, 将其配置信息建模 , 以 python + json 举个简单的例子
有一个在线课程系统, 为每个注册用户建立一个配置文件
{
"username": "walter",
"password": "xxx",
"email": "walter@xxx.com",
"courses": [ ],
"scores": { }
}
对应的python 程序如下
import json
import os
import sys
class UserConfig:
def __init__(self, json_file):
self.read_config(json_file)
self.username = self.config_data['username']
self.password = self.config_data['password']
self.email = self.config_data['email']
def read_config(self, json_file):
json_data=open(json_file)
self.config_data = json.load(json_data)
def dump_config(self):
print self.config_data
print "username=", self.username
print "password=", self.password
print "email=", self.email
if __name__ == "__main__":
args = sys.argv
usage = "usage: python %s
argc = len(args)
if(argc < 2):
print usage
else:
json_file = args[1]
print("* the json config file is " + args[1])
config = UserConfig(json_file)
config.dump_config()
执行结果
$ python user_config.py user_config.json
* the json config file is user_config.json
{u'username': u'walter', u'courses': [], u'password': u'xxx', u'email': u'walter@xxx.com', u'scores': {}}
username= walter
password= xxx
email= walter@xxx.com
配置数据库
数据库常用来存储复杂的配置,在建立复杂关系方面优势明显
最常用是表结构就是经典的 key/value 形式
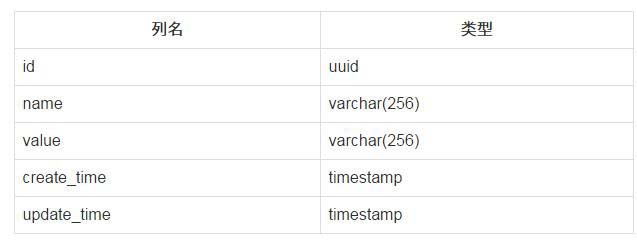
当然 Cassandra 等 NOSQL 就更简单了
配置服务
把具体的配置项及业务相关的配置信息包装成资源, 以REST API的形式暴露读取和修改接口, 大型系统中的复杂的配置甚至可以单独作为一个微服务存在
例如下图
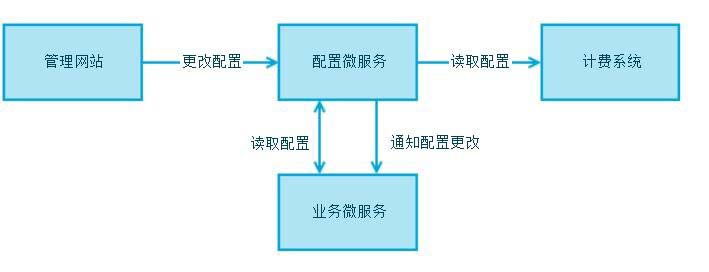
Configure Service
它的好处在于
· 可以将配置信息很好进行建模,在API层面就嵌入AAA 管理
· Authentication认证, Authorization授权 和 Auditing审计, 防止非法操作
· 可以基于 API 将配置流程自动化
· 以服务作为配置数据的真正单个来源 SSoT (Single Source of Truth)
· 提供订阅和通知服务, 在配置有改动时立即通知其他相关的微服务和系统
有一个开源项目 consul 可以用来充当 Configure Service 配置服务, 可以访问 consul github 地址一看究竟, 也是用 go 写的, 看来 go 语言最近上升势头很火
环境管理
一般来说, 我们会有很多不同的测试环境和产品环境来发布我们的服务
比如我们常用的环境有如下几种
· lab env
· ats env
· bts env
· production env
每种环境就有多台服务器协同工作, 手工配置显示太麻烦, 于是众多配置管理的运维工具应运而生
· Ansible
· Chef
· Fabric
· Puppet
· SaltStack
Puppet 以前用得很多, Ansible 最近比较火, 我比较喜欢用轻量级的Fabric, 参见以前写的 程序员瑞士军刀之Fabric
