
写作此文需要6小时,包含4个带图实例,目的是从宏观上剖析和理解这三个术语,适合不同阶段人工智能(缩写AI)、数据科学、机器学习(缩写人数机)爱好者。完整阅读可能需要20分钟。
前言:学科交叉乃大势所趋,新兴学科应市场需求孕育而生。人数机,便产生在这样的时代背景下。什么,你所在的学校至今还没开设相关专业?不必惊慌,老牌资本主义国家德国同样如此。但是,学好微积分、线代、优化、统计、编程,你和人数机可能只是俩三堂专业课的距离。本文旨在从宏观的视角剖析人数机,具体到某个学科或问题,请参见文中给出的链接。
机器学习、深度学习、增强学习,这些“学习”都是什么鬼?3 中的回答或许会让你大跌眼镜。
本文提纲:
1,人数机的概念 2,AI的应用领域 3,AI的解法-机器学习 4,机器学习底层的模型-运筹、统计 5,AI的算法 6,强AI vs 弱AI 7,AI学术界、工业界的全球排名
书归正传,我们一起逐点击破人数机这个大泡泡,力求以最通俗易懂的语言还原他们高大上外表下弱小的真面目(数学模型+算法)。
本文部分内容节选自我在下面问题的回答:
机器学习、优化理论、统计分析、数据挖掘、神经网络、人工智能、模式识别之间的关系是什么? – 知乎
首先我把最近火起来的,关于人数机最热门的几个术语都列出来,因为不知道它们的话,你可能已经OUT了。
人工智能、数据科学、大数据、机器学习、神经网络、深度学习、计算机视觉、自然语言处理、增强学习、(无)监督学习、数据挖掘、文本挖掘、模式识别、虚拟现实、增强现实、GPU计算、并行计算、物联网、工业4.0、智能供应链、智能xx、商业智能、xx智能、图像处理、自动驾驶、统计推断、(凸)优化、K-means算法、Ford-Fulkerson算法等等。(欢迎评论区补充“火”的术语)
下文我尝试把这些术语按照概念、应用、模型、方法、算法来进行分类。
1,概念–人工智能(Artificial Intelligence)、数据科学(Data Science)、大数据(Big Data)
这三个术语最大,放在第一个说–他们属于概念。
简单地说,计算机能像人一样思考并自动处理任务,就可以称为人工智能,即教计算机完成人想完成的复杂的或具有高度重复性的任务。(这里需要注意计算机能理解的只是数据,包括向量和矩阵)
从这个概念出发,那么计算机从发明至今,可以说就顶着“人工智能”的帽子了。比如我们学习任何一门计算语言的循环语句,就很好地服务于这个宗旨。你写一个for i=1..100,就等于让计算机给你重复做了100遍活。还嫌不够多?把100改成1个亿吧。让(“教”)电脑给你干活,这就是人工智能。
由于人工智能“教”计算机处理的,通常都是很大的数据。例如图像处理,对于计算机来说,一张1000*1000的图片在它看来只是100万个像素(灰度图是100万个数字,RGB图是100万*3的一个向量)。
因此数据科学、大数据也属于人工智能概念的范畴,它们和人工智能一样,仅仅是被炒起来的“术语”。而理解上面三段话,你就拥有了和小白吹牛的资本。
这些行业到底有多热,看看薪资就能略知一二:
国内(全球)TOP互联网公司、学术界(人工智能)超高薪的揽才计划有哪些? – 知乎
再举个比循环语句稍稍复杂点的例子:预测(Forecasting、Prediction)。
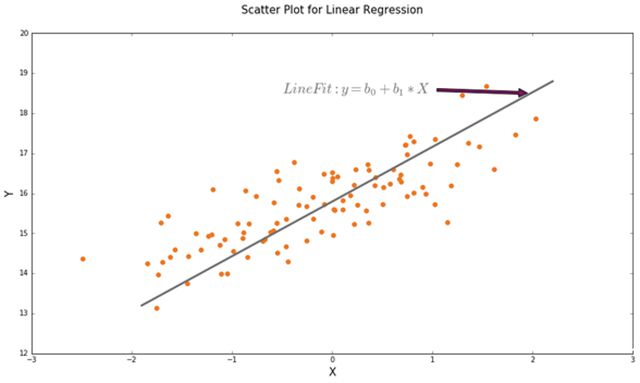
给你一堆点(x_i,y_i),人眼一看,根据数据以往的趋势,下一个点x_n的y坐标–y_n应该出现在箭头所指的地方。但是如果有1000堆类似数据等你预测呢?你需要1000个人来描这个点么?NO,你只需要教会计算机如何根据x_n预测出y_n的值。–很简单,学过统计的应该都知道线性回归(Linear Regression),用最小二乘法根据以往的数据(x_i,y_i)算出线性系数b_0和b_1,那么预测函数y=b_0+b_1*x,电脑就可以根据这个公式来预测后面所有的y值。当然有进阶版的分段线性回归(piecewise linear fitting),欢迎听下回分解。
2,应用
模式识别(Pattern Recognition)、计算机视觉(Computer Vision)、自然语言处理(Natural Language Processing)、数据挖掘(Data Mining)、物联网(Intenet of Things)、商业智能(Business Inteligence)、自动驾驶(Auto Driving)、云计算(Cloud Computing)、虚拟增强现实(Virtual Augmented Reality)等
这些都属于人工智能和大数据的应用场景。
模式识别:把一堆杂乱无章的数据或像素(图像)里深藏的“模式”或规则用计算机自动识别出来。
计算机视觉、图像处理:“教”计算机像人一样识别图像或视频中的模式。
自然语言处理:同样的,计算机看待人说的话只是一段段音频信号(signal),或者更底层些,只是一个x坐标为时间t的二维数据。如何把电信号翻译成文字(text),需要人来“教”它。
数据挖掘:从一大堆数据里挖掘出你想要的有用的信息。怎么样,是不是和模式识别有点异曲同工之妙?不过其主要数据对象是数据库(Database),类似的还有文本挖掘(text mining)。
物联网:把所有东西(例如家电)都联网,并实时保持数据的连通,然后计算机处理这些数据。例如根据主人的生活习性自动开关暖气。
商业智能:人工智能应用在商业大数据领域。例如银行欺诈性交易的监测。
自动驾驶:顾名思义,内置在汽车甚至设置在云端的计算机自动给你开车。利用的是计算机处理汽车上的摄像头实时产生的图片信息,以及雷达产生的信号。
云计算:把计算任务传送到“云端”,得出结果后再传送回来。云端可能是一个大的计算机集群(Cluster),难点在于如何协同CPU和GPU。
虚拟、增强现实(VR、AR):VR眼镜应该都体验过吧?未来的趋势,3D电影演唱会等,足不出户体验现场感。Pokemon Go是AR最好的例子,使虚拟和现实混合在一起。俩者的核心技术都在计算机视觉里,包括校准、3D重建、识别、追踪等等。
通过以上九个术语的翻译,相信妈妈再也不用担心我被“概念”的炒作蒙蔽双眼了。
再举个例子:模式识别(Pattern Recognition)里的图像分割(Image Segmentation)。
给你一张图片,你自然知道描出图里所有物体的轮廓,把该图分割成了几块,该图的“模式”就被识别出来了。但是给你100,1000张图呢?你还有耐心一张张用手描轮廓?这时候你需要教计算机如何画这个轮廓,并且不仅仅限于几张图,这个模型或算法必须适用于绝大多数的图片。这就是模式识别和图像分割。

3,方法–机器学习(Machine Learning)
前面讨论了概念和应用,那么用什么方法来实现2中的应用呢?机器学习便是最有力的方法之一。把机器学习单独放在方法里,是为了体现其重要性。虽然它是一门建立在统计和优化上的新兴学科,但是在人工智能、数据科学等领域,它绝对是核心课程中的核心。
机器学习,顾名思义,教机器如何“学习”,或让机器自己“学习”。因此从字面上看就天然的属于人工智能范畴。“学习”这个看似高深的术语,在1线性回归的例子里,仅仅指求解(学习)b0, b1这俩个系数。任何其他炒得火热的“xx学习”,也只是求解一些参数-说得都很好听,仅此而已。
对于统计和运筹学这俩门基础学科来说,机器学习又是应用(见下面四类问题),因为它大量地用到了统计的模型如马尔可夫随机场(Markov Random Field–MRF),和其他学科的模型,如偏微分方程(变分法等),最后通常转化成一个能量函数最小化的优化问题。
机器学习的核心在于建模和算法,学习得到的参数只是一个结果(见5)。
机器学习里最重要的四类问题(按学习的结果分类):
预测(Prediction)–可以用如回归(Regression)等模型。
聚类(Clustering)–如K-means方法。
分类(Classification)–如支持向量机法(Support Vector Machine)。
降维(Dimensional reduction)–如主成份分析法(Principal component analysis (PCA)–纯矩阵运算)。
前三个从字面意思就好理解,那么为什么要降维呢?因为通常情况下,一个自变量x就是一个维度,机器学习中动不动就几百万维,运算复杂度非常高。但是几百万维度里,可能其中几百维就包含了95%的信息。因此为了运算效率,舍弃5%的信息,我们需要从几百万维中找出这包含95%信息的维度。这就是降维问题。
机器学习按学习方法的分类:
监督学习(Supervised Learning,如深度学习),
无监督学习(Un-supervised Learning,如聚类),
半监督学习(Semi-supervised Learning),
增强学习(Reinforced Learning)。
这里不从晦涩的定义上深入展开,举俩个例子或许效果更好。
邮件分类的例子:
邮件管理器中的垃圾邮件和非垃圾邮件的分类,就是一个典型的机器学习的分类问题。这是一个有监督的学习问题(Supervised Learning),什么叫有监督呢?计算机是在你的监督(标记)下进行学习的。简单地说,新来一封邮件,你把他标记为垃圾邮件,计算机就学习该邮件里有什么内容才使得你标记为“垃圾”;相反,你标记为正常邮件,计算机也学习其中的内容和垃圾邮件有何不同你才把它标记为“正常”。可以把这俩个分类简单的看成”0″和“1”的分类,即二分问题(Binary Classification)。并且,随着你标记越来越多,计算机学习到的规律也越来越多,新出现一封邮件标记的正确率也会越来越高。
当然分类可不止用在判别垃圾邮件,其他应用例如银行欺诈交易的判别(商业智能范畴),计算机视觉里给计算机一张图片,分类为狗还是猫(著名的ImagNet,可是把图片分成了2万多类)。等等。
前面讲了监督学习,无监督学习即在没有人工标记的情况下,计算机进行预测、分类等工作。
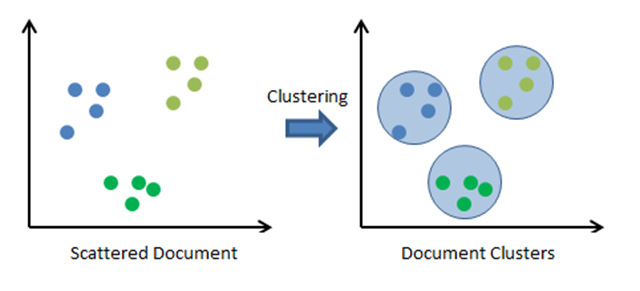
再来一个例子–聚类(Clustering)–无监督的学习
事先没有对图中的点进行标记类别,左图在计算机看来,仅仅是12个点(x,y坐标),但是人眼可以判别它大致可以分为三类(这时,123,321,132代表的都是相同的聚类,顺序没有关系)。如何教计算机把数据归类呢?这就是聚类问题。其中最经典的算法叫K-means。
半监督介于俩者之间,增强学习牵扯到更深的运筹、随机过程、博弈论基础,这里暂时不展开。
机器学习作为新创的学科或方法,被广泛地应用于人工智能和数据科学等问题的求解。按照行业的说法,神经网络、深度学习、增强学习等模型都属于机器学习的范畴。
本节最后出一个思考题,1中的线性回归属于监督还是无监督学习呢?
4,模型–运筹学(Operations Research(O.R.))、
凸优化(Convex Optimization)、统计分析(Statistical Analysis)、神经网络(Neural Network)、深度学习(Deep Learning)
把它们归到一类,因为他们都是一种解决实际问题的模型。例如解决图像分割问题,你可以用统计的模型(如马尔可夫随机场),也可以用神经网络模型,当然也可以用深度学习,即卷积神经网络模型(Convolutional Neural Networks)。
统计和运筹作为有深厚渊源的学科,这俩个名词本身就能成为一个专业,其下又有无数的分支和方向。他们本身研究的对象就是大数据,因此和人工智能、数据科学有着天然的渊源。最近因为人数机的兴起,统计、凸优化模型也再度热了起来(特别是概率图模型)。相信他们和人工智能会起到相辅相成、互相促进的效果。
神经网络(监督学习门下,需要有标签的数据)和深度学习,相比前俩个庞大学科,充其量只能算一个基于图论(Graph Theory)的模型。神经网络也是由来已久,刚开始的全连接神经网络(Fully Connected Neural Network)以及多层神经网络,都是传统神经网络,由于参数多计算(学习这些参数)的复杂度很高,因此实用性不强没有得到足够的重视。直到近些年卷积神经网络的横空出世,深度神经网络(Deep Neural Network)已基本秒杀其他一切传统方法,缺点是需要有标签的庞大的数据集以及训练时间过长(计算机资源)。
当然人工智能,特别是深度学习有过热的趋势,导致炒概念这样不良风气的产生,甚至有偷换概念之嫌。下面链接乃计算机视觉领军人物之一加州大学洛杉矶分校UCLA统计学和计算机科学教授Song-Chun Zhu的访谈录,给深度学习泼一点冷水。 初探计算机视觉的三个源头、兼谈人工智能|正本清源
由于O.R.出身,把运筹放在最后一点–楼主必须正本清源O.R.的在人工智能中扮演的重要角色。
在机器学习里我已提到,这里再强调一遍,几乎所有的人工智能问题最后会归结为求解一个优化问题(Optimization Problem)。而研究如何求解优化问题的学科,正是运筹学。
运筹学的作用,不仅限于求解其他模型(如统计)最后产生的优化问题,也可以作为模型本身(优化模型)来解决人工智能问题。
优化模型包含目标函数和约束条件。优化问题就是求解满足约束条件的情况下使得目标函数最优的解。敬请读者们关注我的运筹专栏,听我下回仔细分解。这里只提一点,大家所熟知的支持向量机,其实完全可以看作运筹中的二次规划(Quadratic Programming)问题。
最后唠叨一句楼主的科研方向,就是用运筹学中的混合整数规划(Mixed Integer Nonlinear Programming)模型建模,解决人工智能中的应用,如图像分割。
由于版面有限,不再具体展开。关于运筹学你所要知道的几乎一切,都在下面:
5,算法–K-means,Ford-Fulkerson
做过人工智能实际/科研项目的人知道,解决一个实际问题就像小时候解应用题,从假设未知数开始(已是模型的范畴),一般步骤便是数学建模-设计算法-编程实现,并以此反复推敲。因此为了文章的完整性,加上算法这一节。
K-means在3的聚类问题中已提到,这里重点讲讲最大流以及算法和模型之间的关系。
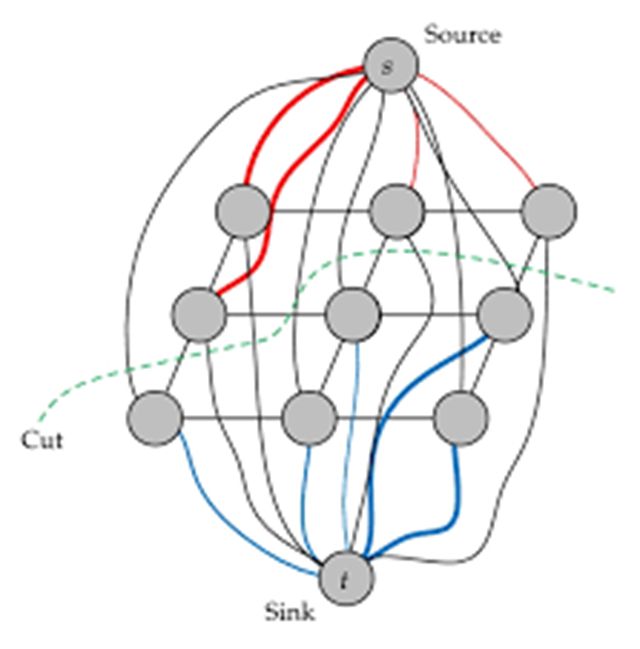
Ford-Fulkerson算法属于运筹学或图论-网络流问题(Network Flow Problem)中一个非常经典的问题-最大流问题(Max Flow Problem)的算法,它在图像处理特别是图像分割中,有着极为重要的应用。
如图:把一张3*3像素的图像看作3*3个点的图(图论术语里的图),并且把上下左右相邻的点用边连接起来,组成edge(图论里的边)。这么一来,图像分割问题就完美地转换成了一个基于图论(或者network flow)的优化问题。如下图,九个像素的图被最大流算法用绿线分割成了俩个部分(segment),绿线即为最小分割(min cut),这里s点和t点是为了构建网络流模型额外增加的俩个点(terminal node)。
下面讨论模型和算法的关系,引自我在下面的回答:
这里强调下数学建模的重要性,为何要数学建模呢?的确很多naive的算法完全不需要建立在数学模型之上,比如clustering里面经典的EM算法,是一个iterative method,基本一眼就能看出算法的思路然后编程实现。那么基于数学模型上的算法有何妙处呢?答案是一个好的数学模型,往往是被研究了几十甚至几百年的学科,比如图论,很多性质都已经被研究得很透彻可以直接使用。回到上面的例子,我建立的这个网络流的模型,是一个被研究了很久的模型,因此我可以直接使用其很多已知的好定理或算法来服务我的问题,比如这里基于里max flow的Ford-Fulkerson算法,如果能在其基础上做改进,等于站在巨人的肩膀。因此这就是数学建模的重要之处。
往往同一个问题,从不同的角度去看可以有千百种数学建模方法,而不同的数学模型差别往往巨大。而数学建模又是解决一个实际问题的第一步,在这基础上才考虑算法和数据结构设计。因此,数学模型和背后的数学基础在我看来是重中之重,也是我推荐学习的课程的核心。当然了,计算机系出生的朋友,数学这个层面学习得不是很深,可以偏向于算法的设计和实现,它们也是重要的。
6,强人工智能(Strong AI或 Artificial General Intelligence) vs 弱人工智能(Applied AI,narrow AI,weak AI)
上面唠叨了那么多,说来说去都是建立在以二进制为机理的图灵计算机上的“弱人工智能”,即计算机需要人去“教”它怎么做。而人工智能、神经网络的最终目的,是模仿人脑的机理和组成(脑神经元、神经网络),让计算机能像人一样具有思维、自主意识,自行学习和决策,称为“强人工智能”。
这里不得不提到母校德国海德堡大学物理系和英国曼彻斯特大学牵头的欧盟“人脑计划”,其最终目的就是打破计算机的二进制机理,模仿人脑神经元(Neuron)放电(spark)的随机性,打造出一台能像人脑一样“思考”的计算机。从此计算机不再二进制(0或1),而是可以取[0,1]间的随机值。另外工业界如IBM也在打造此类计算机。
此机一旦面世,以往一切惯例将被打破,“强人工智能”的新纪元或许会随之到来。
7,人工智能学术界、工业界全球排名
按照本文作者的尿性,最后不出意外会给个排名。今天也不例外,排名不分先后。
学术界:人工智能等新兴学科通常设置在计算机系,此处可参考CS排名
美国凭借教授数量一如既往地排在前头:CMU、斯坦福、MIT、UC伯克利、哈佛、普林斯顿
英国伦敦也是AI重地:牛津、剑桥、帝国理工再加爱丁堡
加拿大可谓深度学习孵化地,DL三杰都和国有渊源:多大、蒙特利尔、UCB
欧洲因教职稀少排名自然弱,瑞士俩校拔得头筹,ETH、EPFL,海德堡HCI五教授之阵容理应占得一席,哦,原来三个隶属物理系。
亚洲新加坡、香港你来我往,日本东大山河日下,中国清华异军突起,姚班功不可没。
工业界:凭借着财大气粗吸引人才,以及计算能力和数据量的优势,工业界在AI领域或许已经赶超学术界
美国自然是全球AI中心(硅谷、西雅图、波士顿、纽约):Google刚请来了斯坦福李飞飞(sabbatical)以及多大的Geoffrey Hinton,Facebook有NYU的Yann LeCun, 微软、IBM研究院早已名声在外,Amazon云计算一家独大,还有Uber、Airbnb、LinkedIn等新贵互联网公司的助力。
英国伦敦:DeepMind被Google收购,Google、微软等在伦敦都设有研究院。
欧洲:IBM、Google在苏黎世和慕尼黑都有研究院,扩招中;amazon在卢森堡有研究院;德国传统公司,如拜耳、博世、西门子等纷纷发力AI建立研究院,宝马奔驰奥迪等车场也投注自动驾驶。最后说说海德堡,SAP总部所在地,还有NEC、ABB等欧洲研究院。
加拿大:加拿大政府在多伦多刚成立人工智能研究院-Vector Institute ,G Hinton任首席科学顾问,Google在蒙特利尔准备成立新研究院,可见Yoshua Bengio领导的深度学习研究院名声在外。
中国:北有科技之都北京,得天独厚的优势,微软亚洲研究院培养起了中国一大批AI大佬;百度、京东以及地平线机器人、滴滴等一大批互联网新贵开始崭露头角。南有深圳,华为、腾讯、大疆、顺丰等也毫不示弱。
到此,相信读者们可以更有自信地吹“人工智能、数据科学、机器学习”的牛逼了。
