Pradeep Menon是一位在大数据,数据科学,数据架构领域拥有丰富经验以及影响力的专家。这是他今年所撰写的简述数据科学系列文章中的第一篇,主要介绍数据科学中的基本定律、常用算法以及问题类型,读者可以从中一窥数据科学的全景。
2016年,英国数学家,乐购俱乐部构架师Clive Humbly提出“数据是新能源”这样一个说法。他说:
“数据是新能源。它拥有极高的价值,却需要经过提炼才能使用。就像石油一样,必须被转化为气体、塑料或者化学品等,才能发挥出其实际的作用; 因此,数据只有被分解和分析之后才具备价值。”
iPhone革命,移动经济的增长,为大数据技术的发展创造了一个完美的契机。在2012年,HBR(Harvard Bussiness Review)发表过一篇文章,将数据科学家推到了风口浪尖上。这篇名为《数据科学家: 21世纪最性感的职业》(Data Scientist: The Sexiest Job of the 21st Centry) ( https://hbr.org/2012/10/data-scientist-the-sexiest-job-of-the-21st-century) 给这群“新人类”打上了标签: 一个数据黑客、分析师、传播者和信誉顾问的混合体。
每个公司目前都在尝试变得更为“数据驱动(data-driven)”。机器学习技术在其中提供了很大的帮助。这其中很多的东西非常专业,很难理解。因此,本系列文章将会简化数据科学。作者尝试参照斯坦福大学的课程以及教科书统计学习导论(Introduction to Statistical Learning) (http://www-bcf.usc.edu /~gareth/ISL/ ),将数据科学以一种简单容易理解的形式呈现给读者。
数据科学是一个多学科领域,主要包括:
- 商业知识 (Business Knowledge)
- 统计学习又名机器学习 (Statistical Learning aka Machine Learning)
- 电脑编程 (Computer Programming)
该系列的重点是简化数据科学中机器学习方面的知识。本文将首先介绍数据科学中的基本定律,常用算法以及问题类型。
核心定律
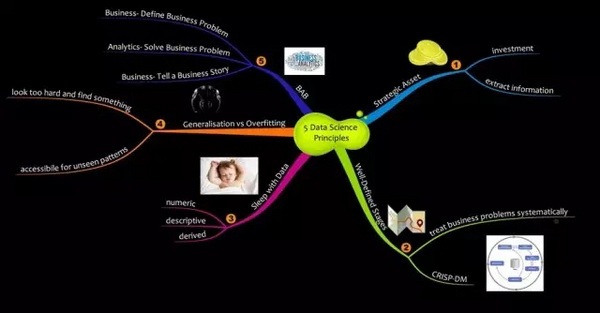
(图片转载自 (Menon, 2017))
数据是一项战略资源:这一概念是一种组织思维。问题是:“我们是否正使用我们所收集和存储的全部数据信息?我们能否从中挖掘有意义的资源?”我非常确定,这些问题的答案都是“否”。以云端为基础的公司都依赖数据驱动。它们势必将数据视为战略性资源。但这一观念并非适用于大多数机构。
知识摄取的系统化流程:挖掘数据需要一套有条理的流程,这其中包括明确的步骤,以及每一步清晰可实现的目标。就好比跨行业数据挖掘标准流程(CRISP-DM) (https://en.wikipedia.org/ wiki/ Cross_Industry_Standard_Process_for_Data_Mining)。
与数据共眠:相关机构应当投资热衷于数据的专业人士。将数据转化为资源的不是炼金术。这个世界也没有万能的炼金术士。他们需要的是懂得数据价值,能识别和创造数据资源的信仰者。以及可以将数据,科技以及金融这些领域链接在一起的专业人才。
接受不确定性:数据科学不是一颗银色子弹(特效武器)。它也不是水晶球,可以用来预言未来。像报告和关键绩效指标一样,它是一个决策推动者。数据科学是一个工具,而不是一种达到目的的手段。它不是绝对的,而是属于概率的范畴。管理层和决策层需要接受这个事实。他们需要将被量化的不确定性加入到决策过程中。只有当相关机构采取实验的文化,并且能够从失败中迅速学习,才能立足于不确定性之上成长。
BAB定律(Business-Analytics-Business):我认为这是最重要的一条定律。多数数据科学的文献都将重点放在模型和算法上。方程式本身缺乏商业背景。BAB则是突出其中的商业部分。把算法置于商业背景中是至关重要的。定义商业问题,用分析来求解,最后将答案集成到商业流程中。也就是所谓的BAB:商业-分析-商业,这么一个过程。
流程

(图片转载自 (Menon, 2017))
参考第二定律,这一段将会把重点放在介绍数据科学中的流程部分。以下是一个典型数据科学项目中的各个阶段:
1. 定义商业问题 (Define Business Problem)
爱因斯坦曾说:“凡事保留其本质,力求最简”。这个引用可以说是定义一个商业问题的关键。问题的描述需要精确的加工,必须明确定义出所需达成的目标。根据我的经验,业务团队过于忙于手头的任务,却忽略了需要应对的挑战。头脑风暴会议,研讨会以及访谈都可以帮助发现这些挑战,并且制定假设。举个例子,我们假设一家电信公司由于客户群的减少导致同比收入下降。在这种情况下,商业问题可以定义为:
- 公司需要通过开发新客户群,同时减少客户流失,来扩大客户基础。
2. 分配机器学习任务 (Decompose To Machine Learning Tasks)
定义好的商业问题需要被分配为各项机器学习任务。就以上例子来说,如果公司需要通过开发新市场,减少客户流失,来扩大客户基础,那么我们如何将其分解为机器学习问题?以下是一个分解方案:
- 减少客户流失x%。
- 确定目标营销的新客户群。
3. 数据准备工作 (Data Preparation)
制定了商业问题,并且将其分解为机器学习任务之后,我们需要深入了解其相关数据,以便制定适当的分析策略。需要注意数据的来源,数据的质量,以及数据的偏差等主要事项。
4. 探索性数据分析(Exploratory Data Analysis)
就像宇航员探索宇宙一样,一位数据科学家需要探索数据模式中的未知,深入了解其隐藏的特征,并记录新的发现。探索性数据分析(EDA)是一项扣人心弦的任务。我们能够更好地了解数据,调查其细微的差别,发掘隐藏的模式,开发新的特征,并且制定建模策略。
5. 建模 (Modelling)
在探索性数据分析之后,我们将进行建模。在这个阶段,我们针对具体的机器学习问题,选择最适用的算法,比如常见的回归(Regression)、决策树(Decision Tree)、随机森林(Random Forest)等算法。
6. 部署和评估 (Deployment and Evaluation)
最终,我们部署好建立的模型,并对它们进行不断监测,观察他们在现实中的表现,并进行有针对性的校准。
通常,建模和部署部分只占全部工作的20%,剩余的 80%的工作是对数据的研究以及深度的了解。
机器学习的问题类型
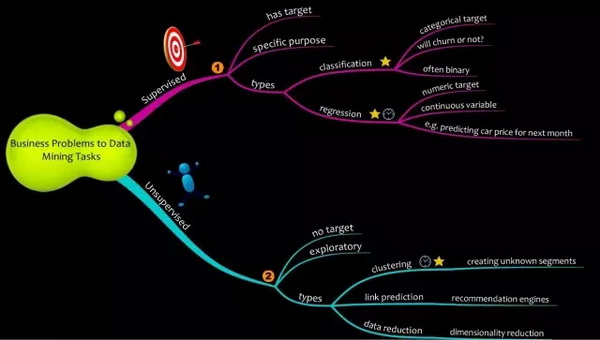
(图片转载自 (Menon, 2017))
简单来说,机器学习被分为两大类:监督学习和无监督学习。
1. 监督学习(Supervised Learning)
监督学习任务拥有一个事先定义好的目标。建模者有针对性地观察并且影响机器学习模型的生成的过程,以实现其特定的目标。监督学习可以进一步分为两类:
回归 (Regression):
回归模型在机器学习任务中非常常见,用于估计和预测一个数值变量。举两个例子:
- 下个季度潜在收入的预估是多少?
- 明年可以结交多少笔交易?
分类 (Classification):
顾名思义,分类模型把目标分开并归整为几个特定的类型。它适用于所有类型的应用。举几个典型的例子:
- 使用分类模型过滤垃圾邮件,将收到的电子邮件基于某些特征分类为垃圾邮件和可接收邮件。
- 流失预测是分类模型的另一个重要应用。电话公司普遍使用流失模型(Churn Model)来预测用户是否会流失(即停止使用服务)。
2. 无监督学习(Unsupervised Learning)
无监督学习没有指定的目标,因此产生的结果有时候会难以解释。无监督学习任务有很多种类型。最常见的几个是:
- 聚类(Clustering):通过相似度把目标归类在一起。比如客户细分就是使用聚类算法。
- 关联(Association):关联算法用来寻找相互匹配的产品。购物篮分析(Market Basket Analysis)就是使用关联算法将产品捆绑销售。
- 链路预测(Link Prediction):链路预测用于查找数据项之间的连接。比如 Facebook,Amazon和Netflix这些网站大规模地使用链接预测算法来为我们推荐相关朋友,热衷商品和的电影。
- 数据简化(Data Reduction):数据简化方法用于减少数据集中特征的数量。它将大量属性的大型数据集用较少的属性呈现出来。
机器学习任务到模型到算法
一旦将业务问题分解为机器学习任务,一个或多个算法可以解决给定的机器学习任务。通常,一个模型是使用多个算法进行训练的。选择提供最佳结果的算法或算法集合进行部署。
Microsoft Azure Machine Learning有30多种预先构建的算法,可用于训练机器学习模型。
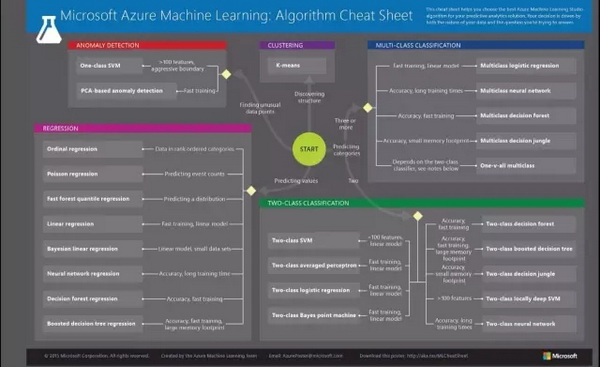
(图片转载自 (Menon, 2017))
Azure Machine Learning cheat-sheet可以帮助你探索这些算法。
结论
数据科学是一个非常广泛的领域。它扣人心弦,是一门科学,亦是一门艺术。在这篇文章中,我们仅仅探索了冰山的一角。如果在不懂得其原理“why”的情况下去探索它的方法“how”是没有意义的。在随后的文章中,我们将继续探讨机器学习的方法“how”。
