Java Memory Model简称JMM, 是一系列的Java虚拟机平台对开发者提供的多线程环境下的内存可见性、是否可以重排序等问题的无关具体平台的统一的保证。(可能在术语上与Java运行时内存分布有歧义,后者指堆、方法区、线程栈等内存区域)。
并发编程有多种风格,除了CSP(通信顺序进程)、Actor等模型外,大家最熟悉的应该是基于线程和锁的共享内存模型了。在多线程编程中,需要注意三类并发问题:
1、原子性
2、可见性
3、重排序
原子性涉及到,一个线程执行一个复合操作的时候,其他线程是否能够看到中间的状态、或进行干扰。典型的就是i++的问题了,两个线程同时对共享的堆内存执行++操作,而++操作在JVM、运行时、CPU中的实现都可能是一个复合操作, 例如在JVM指令的角度来看是将i的值从堆内存读到操作数栈、加上一、再写回到堆内存的i,这几个操作的期间,如果没有正确的同步,其他线程也可以同时执行,可能导致数据丢失等问题。常见的原子性问题又叫竞太条件,是基于一个可能失效的结果进行判断,如读取-修改-写入。可见性和重排序问题都源于系统的优化。
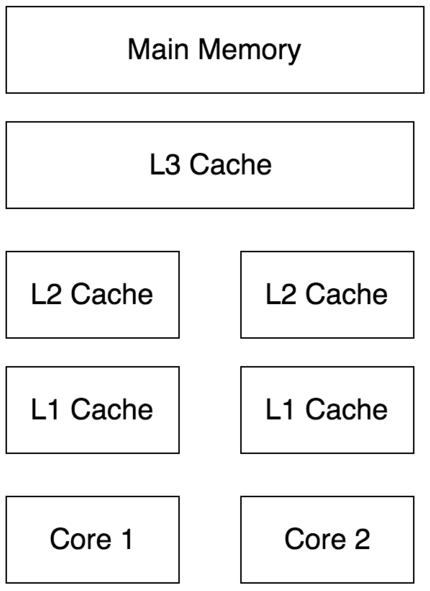
由于CPU的执行速度和内存的存取速度严重不匹配,为了优化性能,基于时间局部性、空间局部性等局部性原理,CPU在和内存间增加了多层高速缓存,当需要取数据时,CPU会先到高速缓存中查找对应的缓存是否存在,存在则直接返回,如果不存在则到内存中取出并保存在高速缓存中。现在多核处理器越基本已经成为标配,这时每个处理器都有自己的缓存,这就涉及到了缓存一致性的问题,CPU有不同强弱的一致性模型,最强的一致性安全性最高,也符合我们的顺序思考的模式,但是在性能上因为需要不同CPU之间的协调通信就会有很多开销
典型的CPU缓存结构示意图如下
CPU的指令周期通常为取指令、解析指令读取数据、执行指令、数据写回寄存器或内存。串行执行指令时其中的读取存储数据部分占用时间较长,所以CPU普遍采取指令流水线的方式同时执行多个指令, 提高整体吞吐率,就像工厂流水线一样。
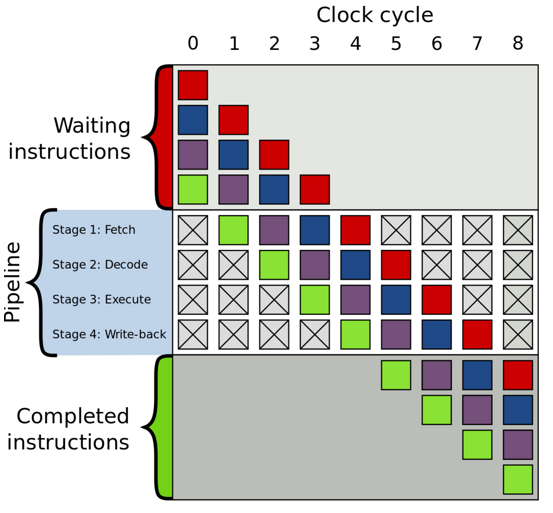
读取数据和写回数据到内存相比执行指令的速度不在一个数量级上,所以CPU使用寄存器、高速缓存作为缓存和缓冲,在从内存中读取数据时,会读取一个缓存行(cache line)的数据(类似磁盘读取读取一个block)。数据写回的模块在旧数据没有在缓存中的情况下会将存储请求放入一个store buffer中继续执行指令周期的下一个阶段,如果存在于缓存中则会更新缓存,缓存中的数据会根据一定策略flush到内存。
public class MemoryModel {
private int count;
private boolean stop;
public void initCountAndStop() {
count = 1;
stop = false;
}
public void doLoop() {
while(!stop) {
count++;
}
}
public void printResult() {
System.out.println(count);
System.out.println(stop);
}
}
上面这段代码执行时我们可能认为 count = 1 会在 stop = false 前执行完成,这在上面的CPU执行图中显示的理想状态下是正确的,但是要考虑上寄存器、缓存缓冲的时候就不正确了, 例如stop本身在缓存中但是count不在,则可能stop更新后再count的write buffer写回之前刷新到了内存。
另外CPU、编译器(对于Java一般指JIT)都可能会修改指令执行顺序,例如上述代码中count = 1和stop = false两者并没有依赖关系,所以CPU、编译器都有可能修改这两者的顺序,而在单线程执行的程序看来结果是一样的,这也是CPU、编译器要保证的as-if-serial(不管如何修改执行顺序,单线程的执行结果不变)。由于很大部分程序执行都是单线程的,所以这样的优化是可以接受并且带来了较大的性能提升。但是在多线程的情况下,如果没有进行必要的同步操作则可能会出现令人意想不到的结果。例如在线程T1执行完initCountAndStop方法后,线程T2执行printResult,得到的可能是0, false, 可能是1, false, 也可能是0, true。如果线程T1先执行doLoop(),线程T2一秒后执行initCountAndStop, 则T1可能会跳出循环、也可能由于编译器的优化永远无法看到stop的修改。
由于上述这些多线程情况下的各种问题,多线程中的程序顺序已经不是底层机制中的执行顺序和结果,编程语言需要给开发者一种保证,这个保证简单来说就是一个线程的修改何时对其他线程可见,因此Java语言提出了JavaMemoryModel即Java内存模型,对于Java语言、JVM、编译器等实现者需要按照这个模型的约定来进行实现。Java提供了volatile、synchronized、final等机制来帮助开发者保证多线程程序在所有处理器平台上的正确性。
在JDK1.5之前,Java的内存模型有着严重的问题,例如在旧的内存模型中,一个线程可能在构造器执行完成后看到一个final字段的默认值、volatile字段的写入可能会和非volatile字段的读写重排序。
所以在JDK1.5中,通过JSR133提出了新的内存模型,修复之前出现的问题。
重排序规则
volatile和监视器锁
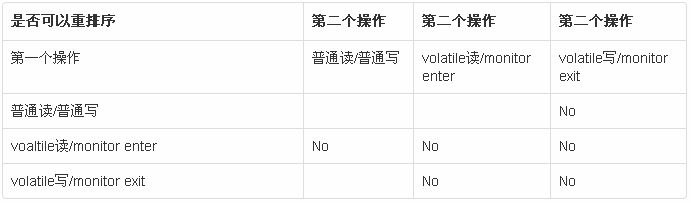
其中普通读指getfield, getstatic, 非volatile数组的arrayload, 普通写指putfield, putstatic, 非volatile数组的arraystore。
volatile读写分别是volatile字段的getfield, getstatic和putfield, putstatic。
monitorenter是进入同步块或同步方法,monitorexist指退出同步块或同步方法。
上述表格中的No指先后两个操作不允许重排序,如(普通写, volatile写)指非volatile字段的写入不能和之后任意的volatile字段的写入重排序。当没有No时,说明重排序是允许的,但是JVM需要保证最小安全性-读取的值要么是默认值,要么是其他线程写入的(64位的double和long读写操作是个特例,当没有volatile修饰时,并不能保证读写是原子的,底层可能将其拆分为两个单独的操作)。
final字段
final字段有两个额外的特殊规则
1、final字段的写入(在构造器中进行)以及final字段对象本身的引用的写入都不能和后续的(构造器外的)持有该final字段的对象的写入重排序。例如, 下面的语句是不能重排序的
x.finalField = v; ...; sharedRef = x;
2、final字段的第一次加载不能和持有这个final字段的对象的写入重排序,例如下面的语句是不允许重排序的
x = sharedRef; ...; i = x.finalField
内存屏障
处理器都支持一定的内存屏障(memory barrier)或栅栏(fence)来控制重排序和数据在不同的处理器间的可见性。例如,CPU将数据写回时,会将store请求放入write buffer中等待flush到内存,可以通过插入barrier的方式防止这个store请求与其他的请求重排序、保证数据的可见性。
内存屏障的分类
几乎所有的处理器都支持一定粗粒度的barrier指令,通常叫做Fence(栅栏、围墙),能够保证在fence之前发起的load和store指令都能严格的和fence之后的load和store保持有序。通常按照用途会分为下面四种barrier
LoadLoad Barriers
Load1; LoadLoad; Load2;
保证Load1的数据在Load2及之后的load前加载
StoreStore Barriers
Store1; StoreStore; Store2
保证Store1的数据先于Store2及之后的数据 在其他处理器可见
LoadStore Barriers
Load1; LoadStore; Store2
保证Load1的数据的加载在Store2和之后的数据flush前
StoreLoad Barriers
Store1; StoreLoad; Load2
保证Store1的数据在其他处理器前可见(如flush到内存)先于Load2和之后的load的数据的加载。StoreLoad Barrier能够防止load读取到旧数据而不是最近其他处理器写入的数据。
几乎近代的所有的多处理器都需要StoreLoad,StoreLoad的开销通常是最大的,并且StoreLoad具有其他三种屏障的效果,所以StoreLoad可以当做一个通用的(但是更高开销的)屏障。
所以,利用上述的内存屏障,可以实现上面表格中的重排序规则

为了支持final字段的规则,需要对final的写入增加barrier
x.finalField = v; StoreStore; sharedRef = x;
插入内存屏障
基于上面的规则,可以在volatile字段、synchronized关键字的处理上增加屏障来满足内存模型的规则
1、volatile store前插入StoreStore屏障
2、所有final字段写入后但在构造器返回前插入StoreStore
3、volatile store后插入StoreLoad屏障
4、在volatile load前插入LoadLoad和LoadStore屏障
5、monitor enter和volatile load规则一致,monitor exit 和volatile store规则一致。
HappenBefore
前面提到的各种内存屏障对应开发者来说还是比较复杂底层,因此JMM又可以使用一系列HappenBefore的偏序关系的规则方式来说明,要想保证执行操作B的线程看到操作A的结果(无论A和B是否在同一个线程中执行), 那么在A和B之间必须要满足HappenBefore关系,否则JVM可以对它们任意重排序。
HappenBefore规则列表
HappendBefore规则包括
1、程序顺序规则: 如果程序中操作A在操作B之前,那么同一个线程中操作A将在操作B之前进行
2、监视器锁规则: 在监视器锁上的锁操作必须在同一个监视器锁上的加锁操作之前执行
3、volatile变量规则: volatile变量的写入操作必须在该变量的读操作之前执行
4、线程启动规则: 在线程上对Thread.start的调用必须在该线程中执行任何操作之前执行
5、线程结束规则: 线程中的任何操作都必须在其他线程检测到该线程已经结束之前执行
6、中断规则: 当一个线程在另一个线程上调用interrupt时,必须在被中断线程检测到interrupt之前执行
7、传递性: 如果操作A在操作B之前执行,并且操作B在操作C之前执行,那么操作A在操作C之前执行。
其中显示锁与监视器锁有相同的内存语义,原子变量与volatile有相同的内存语义。锁的获取和释放、volatile变量的读取和写入操作满足全序关系,所以可以使用volatile的写入在后续的volatile的读取之前进行。
可以利用上述HappenBefore的多个规则进行组合。
例如线程A进入监视器锁后,在释放监视器锁之前的操作根据程序顺序规则HappenBefore于监视器释放操作,而监视器释放操作HappenBefore于后续的线程B的对相同监视器锁的获取操作,获取操作HappenBefore与线程B中的操作。
