大数据与传统的数据技术的差别:
1、数据规模大:传统数据技术主要是利用现有存在关系性数据库中的数据,对这些数据进行分析、处理,找到一些关联,并利用数据关联性创造价值。这些数据的规模相对较小,可以利用数据库的分析工具处理。而大数据的数据量非常大,不可能利用数据库分析工具分析。
2、非结构化数据:传统数据主要在关系性数据库中分析,而大数据可以处理图像、声音、文件等非结构化数据。
3、处理方式不同:因为数据规模大、非结构化数据这两方面因素,导致大数据在分析时不能取全部数据做分析。大数据分析时如何选取数据?这就需要根据一些标签来抽取数据。所以大数据处理过程中,比传统数据增加了一个过程Stream。就是在写入数据的时候,在数据上打一个标签,之后在利用大数据的时候,根据标签抽取数据。这个过程就类似于寻找图书:如果你在你个人书柜里,寻找一本书是很容易的,所以你买了书,可以直接放到书柜上,不用做任何处理;而如果图书馆买了书,如果不做任何处理的话,你是很难找到一本书的,所以图书馆在新书入库的时候,首先会对每本书打上标签,而这个打标签的过程,就是类似于Stream的工作。

大数据与传统数据相比的主要特点可以概括为:数据量“大”、数据类型“复杂”、数据价值“无限”。
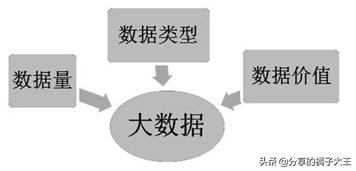
数据量大十分好理解,以前我们存储数据使用的单位是 KB,一个Excel表格也就几十到几百KB,现在我们经常说到GB甚至是TB乃至PB的数据量级,它们的数量关系如下所示。
- 1:1MB=1024KB , 2:1GB=1024MB ,3:1TB=1024GB ,4:1PB=1024TB
更直观一点,1KB相当于512个汉字,1MB就相当于六本红楼梦的字数……而淘宝网在2015年3月每天大约能产生7TB的数据量,相当于4000万本红楼梦的数据量,而中国最大的图书馆中国国家图书馆的藏书量是3000万册。由此看来,我们的大数据着实是数据量巨大了。
大体上数据获取的方式:
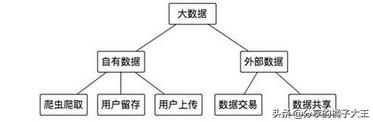
自有数据与外部数据是数据获取的两个主要渠道。在自有数据中,我们可以通过一些爬虫软件有目的的定向爬取,比如爬取一批用户的微博关注数据,某汽车论坛的各型号汽车的报价等。用户留存多是用户使用了公司的产品或是业务,用户在使用产品或是业务中会留下一系列行为数据,这个构成了我们的数据库主体,通常的数据分析多基于用户留存的数据。用户上传数据诸如持证自拍照、通讯录、历史通话详单等需要用户主动授权提供的数据,这类数据往往是业务运作中的关键数据。相较于自有数据获取,外部数据的获取方式简单许多,绝大多数都是基于API接口的传输,也有少量的数据采用线下交易以表格或文件的形式线下传输。此类数据要么采用明码标价一条数据多少钱,或是进行数据共享,交易双方承诺数据共享,谋求共同发展。
大数据与传统数据传输方式:
同样的大数据与传统数据的传输方式也截然不同。传统数据要么以线下传统文件的方式,要么以邮件或是第三方软件进行传输,而随着API接口的成熟和普及,API接口也随着时代的发展逐渐标准化、统一化,一个程序员只用两天的时间就能完成一个API接口开发,而API接口传输数据的效率更是能够达到毫秒级。
在数据存储方面,大数据的存储环境相较于传统数据的存储已经跃升了好几个数量级。
大数据与传统数据显著特点:
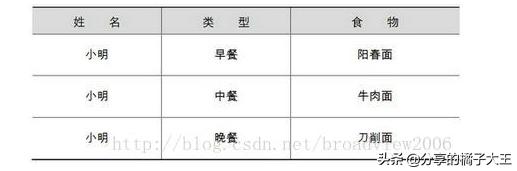
传统数据的记录方式:
大数据的记录方式:
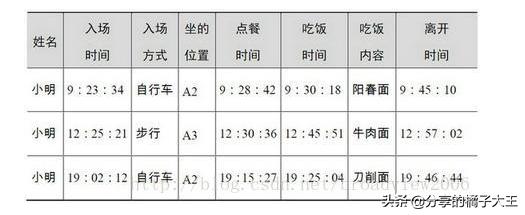
很明显地看到,传统数据和大数据记录数据的最大区别是大数据不仅对对象进行了描述,
大数据与传统数据的核心差异在于其价值的不可估量。传统数据的价值体现在信息传递与表征,是对现象的描述与反馈,让人通过数据去了解数据。而大数据是对现象发生过程的全记录,通过数据不仅能够了解对象,还能分析对象,掌握对象运作的规律,挖掘对象内部的结构与特点,甚至能了解对象自己都不知道的信息。
大数据场景使用的工具:

以上就是大数据与传统数据的区别小知识介绍。

