绝大数公司建立数仓之初是没有考虑好数据治理怎么做的,因为数据部门刚开始成立,必然要有一些“数据驱动”的成果,而数据治理不能很好的体现这些业绩。所以,都是在业务发展的过程中,逐渐遇到了一些数据问题,才考虑做这件事的。

1.如何开始数据治理?
首先从数据管理开始,在开始数据治理之前,我们要先梳理数仓的核心资产。从数据的采集到数据的加工,再到数据的应用(包括数仓报表数据、指标数据)。
那么对于业务数据源,我们要明确数仓中主要的数据源都来自哪些业务系统,哪些关键流程,明确关键来源数据的数据负责人,结合业务制定数据管理规范。
2.数仓数据治理的思路
数仓的数据治理可以从以下几个关键点入手:数据目录重新划分,提高模型复用度,ETL任务优化、数据质量监控。
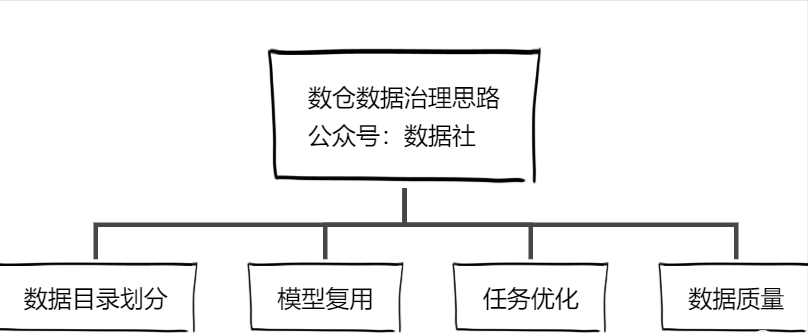
数据目录划分:
很多数仓刚开始设计的时候是没有完整清晰的规划的,慢慢数据目录会变得混乱无序,找某个模型会变得很繁琐。那么,这时候一个好的目录设计,会帮助我们理清数仓的架构,快速的查找定位模型,比如是在哪个层、哪个业务域等。 这些都清晰的展示出来时,数据开发的效率就会有快速的提升了。
模型复用:
离线数仓一般团队都比较大,上次跟快手的一个朋友聊,他们离线数仓都有上百人。所以模型的复用一定要关注,,比如关注一些复用度较高的字段,可以放到中间层统一处理,也就是我们说的有个大宽表提供复用;比如复用较高的函数或者逻辑,我们开发统一的UDF函数,提高数据处理性能。
任务优化:
每当你申请资源时,领导都会问你要价值和用途,其实除了申请额外的资源,我们还可以优化现有的资源。因为在数仓开发过程中,大家的技术水平良莠不齐,对业务理解程度相差甚大,那么此时,每个人开发的ETL任务的质量必然不一样。所以,我们需要时常对任务的执行时长和调用的资源进行监控,展开专项优化,比如降低输入数据量,大量distinct操作使用groupby替换等。当然,管理上可以把任务执行效率作为一个考核项,对不达标的进行晾晒。
数据质量:
主要是数据重复、空值、数据异常等情况的监控,一定要配置规则校验。上次直播,我讲过,并不是任务执行成功就完事大吉了,有时候任务执行成功的代价更为惨重。比如,以前的一个项目,会给老板推送业务指标短信,所以对这个任务加了失败告警监控,但是没有对内容进行校验,导致因为业务的异常数据,引起最后的指标异常,老板很生气,后果很严重。所以,我们还要考虑对于一些关键业务的数据指标监控,发现异常,及时终止下游任务,进行告警。当然,数据质量还有很多工作,之前的一篇文章也讲过,可以阅读《谈谈ETL中的数据质量》
3.总结
总而言之,数仓数据治理的价值很难量化,所以有很多数据团队不愿意去做,但是不做,会很“痒”。
如果,你开始做数仓治理了,那么就要做好长期作战的准备了,比如制定一些月度的资产管理相关的会议,进行回顾,定期对低效率任务进行优化,这都是需要一套管理机制的,而管理机制落地的最好方式应该就是和绩效考核绑定了。

