了解如何使用高可用性 (HA) 和灾难恢复 (DR) 方法在停机的情况下继续不间断地运行。
业务连续性是指公司在停机情况下继续不间断运营的能力。在云环境中,这通常包括高可用性 (HA) 和灾难恢复 (DR)。
他们的最终目标是尽可能减少所有停机风险,以便您可以在中断的情况下正常运行关键服务。
继续阅读以了解有关 HA 和 DR 以及如何提高云中业务连续性的更多信息。
高可用性意味着什么?
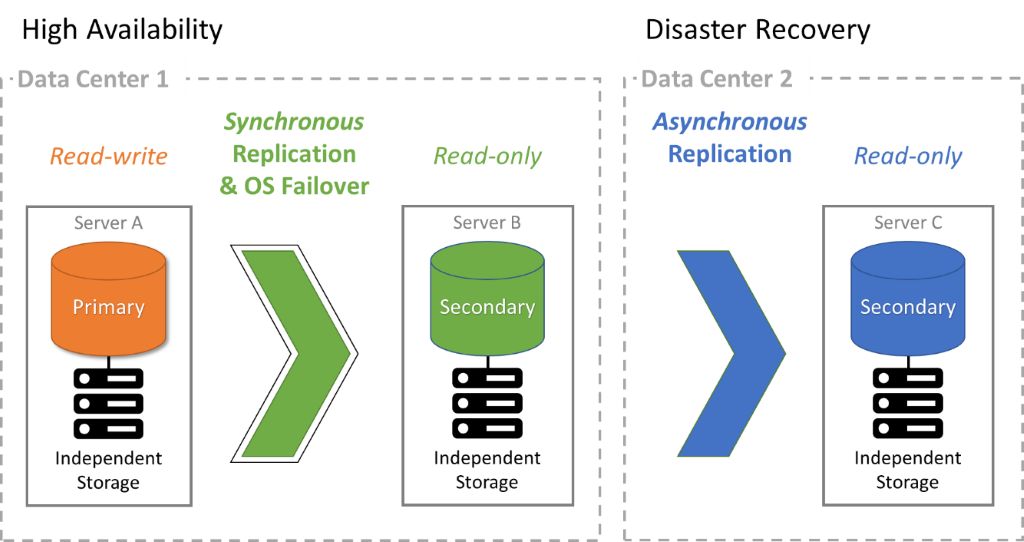
高可用性的基本理念是让您的基于云的服务和工具可以按需访问和工作。但是,HA 的概念所指的远比仅仅让您的云资源在您需要时随时可用更具体。
可用性是您的云基础架构保持运行以达到其目的的时间百分比,通常以九位表示。例如,“五乘九”表示系统在 99.999% 的时间内完全运行,平均每年有 5.5 分钟的停机时间。
如果您希望为您的云部署实现高可用性,您需要通过系统冗余来消除单点故障。HA 还需要编排云系统以自动路由网络流量并减少用户和应用程序的停机时间。
灾难恢复意味着什么?
灾难恢复是预测和解决可能导致 IT 系统崩溃的问题的过程。
DR 可以像从备份中恢复一样简单,但也可以根据恢复时间目标 (RTO) 和恢复点目标 (RPO) 变得更加复杂。
RTO 是系统在再次完全运行之前可以关闭的最长时间。有些设置可以停机数小时甚至数天而不会造成损害,但对于关键任务元素,RTO 通常以秒为单位。
RPO 是可容忍的数据丢失量。虽然在某些设置中丢失一天的数据可能是可以接受的,但在更关键的系统中,这可能是几分钟。
RTO 和 RPO 的可容忍长度会显着影响您的灾难恢复计划。它们需要的时间越短,您就越需要注意活动数据复制、更多冗余或更频繁的备份等因素。
所有这些都会转化为更高的账单——成本通常是阻止组织推动高可用性和缩短 RTO 和 RPO 的主要因素。达到最佳平衡点需要平衡费用和潜在系统停机时间的影响——在某些情况下,HA 和较短的 DR 值可能是不必要的。
这里有四个专家提示,可帮助您增强云部署的业务连续性。
高可用性和灾难恢复的四个技巧
1. 操作可观察性
了解云部署的整体健康状况对于云环境的高可用性至关重要。
操作可观察性是指将日志记录、指标和跟踪与用于诊断和故障排除的工具一起聚合的能力。
根据经验,您的云部署应该集成用于可视化、警报和通知的日志记录和关键指标。
为此,您可以使用云服务提供商的本地监控和可观察性工具。例如,AWS 有一个名为CloudWatch 的工具集,GCP — Google Cloud 的 Operations Suite(以前称为 StackDriver),以及 Azure — Azure Monitor。然而,这些并不是免费的,它们的成本取决于指标的数量和处理的日志数据量。
您还可以从众多第三方工具中进行选择,例如 DataDog、New Relic、Dynatrace 等。来自Grafana和 Elasticsearch的开源解决方案也是受欢迎的选择。
根据您的需要选择合适的工具后,最好通过基础架构即代码(IaC) 部署它。
2.使用IaC进行备份和恢复
运行 IaC 工具的一个显着优势是它允许您在云中重新创建所有最终工件和组件以实现完全恢复。
使用 IaC,您只需要 Git 存储库级别的传统备份/恢复过程。敏感的备份活动必须转移到确保您有足够的代码存储库备份策略。您可以使用 Git 工具和跨区域存储解决方案来实现这一点。
每个区域云部署都包含需要备份的数据。文件系统、对象存储桶和块存储卷等应用程序可以使用各种存储解决方案。
每个工件都需要独立于您的云部署的备份和保留策略。您需要为每个迁移的应用程序和关联的存储组件解决这些问题。
3.使用IaC进行灾难恢复
IaC 的另一个显着优势是它可以在最少的人工干预下自动重建整个云区域。
但是,为了满足您所需的 RTO 和 RPO,您可能需要数据同步解决方案。
您的部署应包括一个具有最低限度定义的基础架构的冷备用云区域。主要目标是同步关键基础设施组件的存储和数据库以及任何特定于应用程序的存储和数据库资产。
4. 学习如何引导一个区域
让我们想象一下您的整个云区域出现故障的情况。您的目标是为您的云部署记录平均恢复时间,最好以小时为单位,而不是几天或几周。
快速引导区域的能力证明您可以从高影响可用性事件中快速恢复。实例化部署会有所帮助,尤其是因为只有几个与网络连接相关的硬性先决条件。
即使缺少数据中心连接,您仍然可以在测试期间快速连续地启动和拆除大部分云部署组件。您的目标应该是创建一个通过 GitOps 和基础架构即代码驱动的可重复流程。
概括
高可用性和灾难恢复都针对同一个问题:在出现中断和其他可能性的情况下保持云系统正常运行。
HA 处理操作系统中的问题,而 DR 则侧重于在发生故障后进行恢复。它们共同提高了您的业务连续性,并有助于确保您的云部署保持全面运行。
我们希望以上四个技巧能够激发您的云迁移策略并使其更加顺利。

