数据库从IOE(IBM小机、Oracle商业DB、EMC存储)一路走来,大家都知道数据库是资源重依赖的软件,对服务器的三大件CPU、内存、磁盘几乎都有要求。数据库作为广泛使用的数据存储系统,其SQL请求背后涉及的物理读、逻辑读、排序过滤等消耗了IO和CPU资源,业务SQL不同,执行计划不同,资源消耗就不同,因而不同业务对资源规格的需求也不一样。正因如此,我们更需要抽象规格,更好地让不同资源诉求的数据库实例混跑在相同的物理机上,提升整体利用率。今天,阿里资深技术专家天羽为我们讲述阿里数据库的极致弹性之路。

除了日常业务需求,阿里的双11场景,让我们持续思考如何低成本高效率地支持峰值流量,把这些思考变成现实,变成技术竞争力。在大促资源弹性上有这么几个思路:
- 使用公共云标准资源弹性,直接用阿里云的标准资源支撑大促后归还。这个是最直接的想法,但这里的难度是业务需求和云资源在性能、成本上的差距,不要定制化机器。
- 混部能力,存量业务的分类混部、分时混部。使用离线资源支撑大促,既是分类混部,双11零点离线降级,高峰后在线归还资源也是分时复用。
- 快上快下,在有能力使用云、离线资源后,尽量缩短占用周期。
- 碎片化资源,数据库一直是块石头,是一个大块完整的规格。如果把数据库自己的大库变成小库,就可以使用其他业务的碎片化资源,包括公共云上的资源。
大促的成本=持有资源X持有周期,更通用的资源(云)、更快的部署(容器化)是缩短持有周期的关键,如何更少地使用资源(使用离线或只扩计算资源),就依赖存储计算分离架构的实施。沿着极致弹性的目标,数据库经历了混合云弹性、容器化弹性、计算存储分离弹性三个阶段,基础架构从高性能ECS混合云、容器化混合云、存储计算分离的公共云和离线混部一步步升级。

基本上架构演进就是每年验证一个单元,第二年全网铺开,每年挖个坑然后和团队一起努力爬出来,每次演进需要跨团队背靠背紧密合作,快速拿下目标,这也是阿里最神奇的力量。借助于底层软硬件技术发展,一步步的架构升级使得弹性混部越来越灵活和快速。
一、混合云弹性,高性能ECS应运而生
2015年之前,我们的大促弹性叫人肉弹性,也就是大促要搬机器,比如集团用云的机型支撑大促,大促结束后搬机器归还给云。但就在2015年底的一次会议上,李津问能否把数据库跑到ECS上,如果可以,就真正帮助了云产品成熟,当时张瑞和我讨论了一下,在会议上就答复了:我们决定试一下。这个合作非常契合会议主题“挑战不可能——集团技术云计算战区12月月会召集令”。
对于数据库跑在虚拟机上,我们判断最大的消耗在IO和网络的虚拟化上,因此如何做到接近本机性能,怎么穿透虚拟化就是一个问题。网络的用户态技术DPDK已经比较成熟,但如何做到足够高的效率,是否offload到硬件来做计算是个问题。文件系统IO的用户态链路有个Intel的SPDK方案,Intel推出后各大厂商还在验证中,还没有规模的应用。我们就在这个时候启动的这个项目,叫高性能ECS。通过和ECS团队紧密合作,最终我们做到了最差场景高性能ECS相比本地盘性能损耗低于10%。
2016年在集团通过了日常验证,2017年大促开始大规模用云资源直接弹性。这个项目除了打造高性能ECS产品,更重要的是沉淀了网络和文件IO的纯用户态链路技术,这是一个技术拐点的产生,为阿里后续存储计算分离相关产品的高性能突破打下了基础。
二、容器化弹性,提升资源效率
随着单机服务器的能力提升,阿里数据库在2011年就开始使用单机多实例的方案,通过Cgroup和文件系统目录、端口的部署隔离,支持单机多实例,把单机资源利用起来。但依然存在如下问题:
- 内存的OOM时有发生
- 存在IO争抢问题
- 多租户混部存在主机账号等安全问题
- 数据库主备机型一致性
随着单机部署密度越来越高,社区Docker也开始发展起来,尽管还不成熟,Docker本身依赖Cgroup做资源隔离,解决不了Cgroup的IO争抢或OOM问题,但它通过资源隔离和namespace隔离的结合,尝试对资源规格以及部署做新的定义,因此我们看到了容器化更多的优势:
- 标准化规格,数据库与机型解耦,主备不需要对称。这对规模化运维带来极大的效率。
- Namespace隔离带来混部能力,资源池统一。
- 不同数据库类型,不同数据库版本随便混。
- 让DB具备与其他应用类型混部的条件。
2015年数据库开始验证容器化技术,2016年在日常环境中大量使用。因此在集团统一调度的项目启动后,我们就定下了2016年电商一个交易单元全部容器化支撑大促的目标,承载交易大盘约30%,并顺利完成。2017年数据库就是全网容器化的目标,目前数据库全网容器化比例已经接近100%。
容器化除了提升部署弹性效率,更重要的是透明底层资源差异,在没有启动智能调度(通过自动迁移提升利用率)前,仅仅从容器化带来的机器复用和多版本混部,就提升了10个点的利用率,资源池的统一和标准部署模板也加快了资源交付效率。容器化完成了底层各种资源的抽象,标准化了规格,而镜像部署带来了部署上的便利,基于数据库PaaS和统一调度层的通力合作,数据库的弹性变得更加快速灵活,哪里有资源,哪里就能跑起数据库。
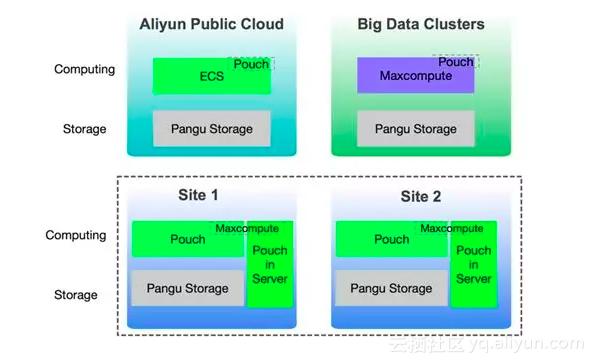
三、计算资源极致弹性,存储计算分离架构升级
实现了容器化混合云,是不是每年大促使用高性能ECS,容器化部署就可以了呢?其实还是有不足的:
- 数据库弹性需要搬数据,把数据搬到ECS上是非常耗时的工作。
- 弹性规模太大,如果超过公有云售卖周期,会增加持有成本。
因此如何做到更快、更通用的弹性能力,是一个新的技术问题。随着2016年调度的发展,大家考虑机器是不是应该无盘化,是不是应该存储计算分离,从而加快调度效率,而数据库的存储计算分离更是争议很大。
数据库的Share Nothing分布式扩展已经深入人心,存储计算分离会不会回到IOE状态?如果IDC是一个数据中心,应用就是计算,DB就是存储,DB自己再做存储计算分离有意义吗?数据是主备双副本的,存储计算分离后变成三副本,存储集群的容量池化能balance掉额外副本的成本吗?
为此我开始测算存储计算分离架构在大促场景下的投入产出,我们来看下大促场景,弹性大促时,业务需求计算能力数倍甚至10倍以上扩容,承担大促峰值压力,而磁盘因为存储长期数据,峰值的数据量在整体占比不高,因此磁盘容量基本不需要扩容。
在以前本地磁盘跑主备的架构,无法计算、存储分开扩容,大促指标越高,添加标准机器越多,成本浪费越大,因为磁盘是标准数据库机器的主要成本。而存储计算分离的情况下,测算下来,我们看到在较低日常压力下存储计算分离成本是比本地盘高的,但再往上,存储计算分离只需要增加计算,存储集群因为池化后,不只容量池化了,性能也池化了,任何高负载实例的IO都是打散到整个集群分担的,磁盘吞吐和IOPS复用,不需扩性能,成本优势非常明显。
磁盘不扩容,只扩计算自然成本低很多。传统的思考是存储集群容量池化的优势,但在大促场景我们更多用到的是性能的池化,突破单机瓶颈,因此我们提出了电商异地多活所有单元存储计算分离,其余业务继续使用本地磁盘进行同城容灾的目标架构。
提出这个设想,而这个架构的可行性如何判断?基于一些数字就可以推断,大家知道SSD磁盘的读写响应时间在100-200微秒,而16k的网络传输在10微秒内,因此尽管存储计算分离增加两到三次的网络交互,加上存储软件本身的消耗,整体有机会做到读写延时在 500微秒的范围内。在数据库实例压测中我们发现,随着并发增加,存储集群具备更大的QPS水位上线,这印证了性能池化突破单机瓶颈带来的吞吐提升。
数据库团队在2017年开始验证存储计算分离,基于25G的TCP网络实现存储计算分离部署,当年就承担了10%大促流量。我们基于分布式存储做到了700微秒的响应时间,这里内核态和软件栈的消耗较大,为此X-DB也针对性地做了慢IO优化,特别是日志刷盘的优化,开启原子写去掉了double write buffer提升吞吐能力。
这个过程中,我们沉淀了存储的资源调度系统,目前已经作为统一调度的组件服务集团业务。我们对当前架构性能不太满意,有了X-DB的慢IO优化、存储计算分离跨网络的IO路径、存储资源调度等技术沉淀,加上阿里巴巴RDMA网络架构的发展,2017下半年数据库开始和盘古团队一起,做端到端全用户态的存储计算分离方案。
四、全用户态IO链路的存储计算分离架构落地
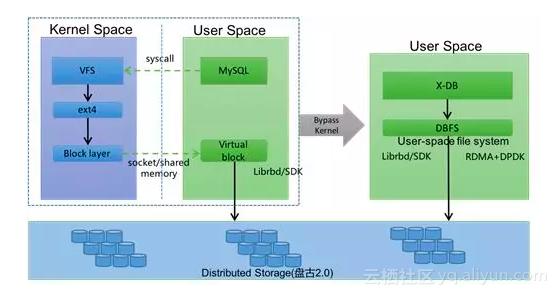
从数据库软件X-DB的IO调用开始,就走我们自己研发的用户态文件系统DBFS,DBFS使用盘古的用户态客户端,直接通过RDMA网络访问后端盘古分布式文件系统,整个IO链路完全绕过了内核栈。这里DBFS绕过了内核文件系统,自然也绕过了pagecache,为此DBFS针对数据库场景,实现了更简洁高效的BufferIO机制。
因为IO都是跨网络远程访问,因此RDMA起到了重要作用,以下是RDMA与TCP网络在不同包大小下的延时对比,除了延时优势外,RDMA对长尾IO的tail latency能够有效控制,对一个数据库请求涉及多次IO来说,对用户请求的响应时间能够更有效保证。RDMA技术的应用是DB大规模存储计算分离的前提条件,通过我们的数据实测,DBFS+RDMA链路的延时已经和Ext4+本地盘达到相同水平。
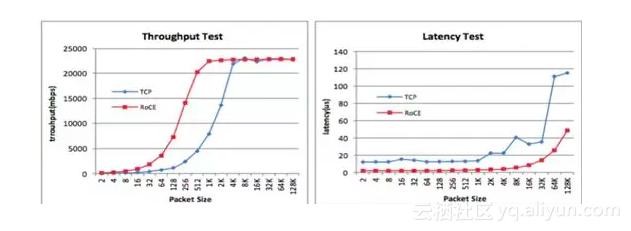
今年我们首次大规模部署RDMA,如履薄冰。经过多次压测、演练, RDMA配套监控和运维体系建设已经完善起来,我们能够在1分钟内识别服务器网卡或交换机的网络端口故障触发告警,能够故障快速隔离,支持业务流量快速切走,支持集群或单机的网络RDMA向TCP降级切换等等。在我们的切流演练中,从DBFS看到RDMA链路的写延时比TCP降低了一倍。我们在全链路压测中,基于RDMA技术保障了在单个数据库实例接近2GB吞吐下磁盘响应时间稳定在500微秒左右,没有毛刺。
盘古分布式存储为了同时支持RDMA、EC压缩、快照等功能,做了大量的设计优化,尤其对写IO做了大量优化,当然也包括RDMA/TCP切流,故障隔离等稳定性方面的工作。作为阿里的存储底盘,其在线服务规模已经非常庞大。
整个技术链路讲清楚之后,说一下我们在规模应用中遇到的难题,首先,容器的网络虚拟化Bridge和RDMA天然不兼容,由于容器走Bridge网络模式分配IP,而这个是走内核的。为了应用RDMA,我们必须使用Host网络模式进行容器化,走Host + X-DB + DBFS + RDMA +盘古存储这样的全用户态链路。
其次,对于公有云环境,我们通过VPC打通形成混合云环境,因此应用通过VPC访问数据库,而数据库使用物理IP用于RDMA访问盘古以及X-DB内部X-Paxos。这个方案复杂而有效,得益于DBPaaS管控的快速迭代和容器化资源调度的灵活性,这些新技术能够快速落地,在变化中稳步推进。
今年年初,我们定下了2018大促的支撑形态,即异地多活的中心机房将计算弹性到大数据的离线资源,单元机房将计算弹性到公共云资源,不搬数据直接弹性扩容,快上快下的大促目标。今年DB全局一盘棋,完成了资源调整,实现了电商各站点的存储计算分离架构升级,并通过X-DB异地多副本架构灵活部署,实现了弹性大促目标。
基于底层盘古分布式的共享存储,弹性不需要迁移数据,只需要挂载磁盘,数据库可以像应用一样快速弹性,做到一个集群10分钟完成弹性扩容。同时在全链路压测过程中,对出现性能瓶颈的业务,我们可以边压边弹,快速弹到更大的规格上。基于快速弹性的能力,今年DB所有站点的大促扩容都在三天内完成,这在以前是不可能实现的,这就是存计分离的架构带来的效率。
最后,感谢阿里内部通力合作的盘古、网络、调度、IDC等团队,正是大家的支持让阿里数据库的基础架构才能不断升级,不断提升效率和成本的竞争力。
数据库存储计算分离的架构升级,大大节约了大促资源成本。目前我们的弹性能力正在日常化,通过数据预测,自动触发弹性扩容,我们的目标是让单机容量问题导致故障成为历史。
接下来我们平台将向智能化发展,对于数据库来说,只有基础架构足够强大,足够快速,灵活,弹性,智能化才能有效发挥。

