一、背景简介
在项目研发的过程中,对于数据存储能力的依赖无处不在,项目初期,相比系统层面的组件选型与框架设计,由于数据体量不大,在存储管理方面通常容易被轻视,当项目发展进入到中后期阶段,系统的复杂性很大程度来源于数据层面;
从常规的微服务架构体系来看,对于系统中的数据存储可以划分如下几个模块:组件库、应用库、业务库、公共库、中间件数据、第三方;不同的场景下对数据存储能力的要求和依赖程度也各不相同;
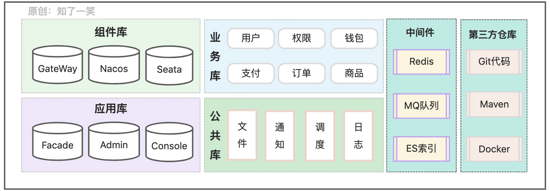
组件库:微服务架构下,诸多基础的框架组件都依赖数据的持久化存储,以此来确保服务能力的稳定可控,避免异常情况下的数据丢失问题;
应用库:作为系统中的应用层,需要对请求的动作有记录和识别能力,并且存储诸多拦截和过滤的规则信息,用来维护下层业务服务的安全稳定;
业务库:做为系统中最核心的数据资产,对业务数据的存储和管理有极高的要求,并且要对数据的变化有一定的评估能力,提前做好数据膨胀的情况下系统测试和拆分方案,保障业务的稳定和持续发展;
公共库:系统中大部分业务都可能会依赖的能力,对于公共库和与之相应的服务来说,其吞吐量和并发能力,要支撑所有依赖业务的同时并发;
中间件:常见的中间件比如:缓存、消息队列、任务调度、搜索引擎等,都有数据存储的性质,只是在实现方式上会有差异;
第三方:大部分系统都或多或少的依赖一些第三方仓库,比如Git代码仓库、Maven包仓库、Docker镜像仓库、行为埋点数据、OSS文件服务等;
二、框架组件
微服务架构的常用组件中,例如GateWay路由网关、Nacos注册配置中心、Seata事务管理器等,都需要数据存储机制;
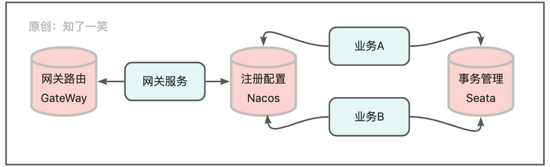
路由网关:通常在网关库中维护各个服务的路由地址和规则策略,以及黑白名单和流量管理等数据,虽然体量并不大,鉴于网关服务需要支撑流量的高并发,所以对数据的读性能有要求,尽量降低请求在网关层的耗时;
注册配置:统筹管理各个服务的配置数据,动态维护服务的注册状态,对存储的稳定性和数据安全有极高要求,要确保各个环境是隔离开的,并且不能暴露生产环境的配置信息;
事务管理:Seata组件提供高性能和易用的分布式事务管理能力,常规的事务调度过程需要依赖几张关键的记录表,通常需要进行分布式事务管理的接口,基本都是处理服务中的核心业务,既要保证稳定性也要支持高并发;
三、应用管理
应用层相对处于系统的上层,比如常见的门面服务,管理服务,控制中心等,通常在相应的库中存储请求记录,特定的过滤和拦截策略,异常响应日志,页面的展示管理等;
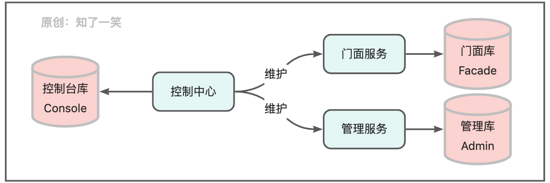
通常来说由控制中心进行统一的管理和维护应用库的配置数据,在各自的应用服务中直接查询即可;从而避免重复实现各种基础功能,同时将系统级的管理都放在控制中心服务,确保数据修改的入口单一,以便更好的监控动作日志;
四、业务数据
作为系统最核心的数据资产,业务数据的精准维护一直都是核心事项,除了提供必要业务流程的数据存储,还要支持数据的动态查询分析,并且会随着业务发展,数据的结构和体量也会不断产生变化;
分库分表:业务过度复杂的时候,会考虑库的拆分,从而保证各个业务块的相对稳定性;当某些表的数据量庞大时,会采用分表的方式,避免该表的处理时间过长从而影响整体性能;业务的库表拆分并且基于微服务管理,是当下主流的架构模式;
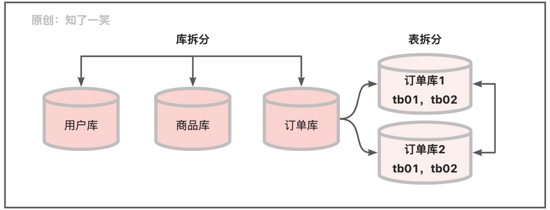
数据维护:随着业务的发展,数据体量和结构会随之膨胀,从而引发质量问题,所以在日常开发中很多版本都会进行数据维护,比如:数据清洗、数据迁移、结构拆分等,从而更好的管理数据保证业务的持续性;
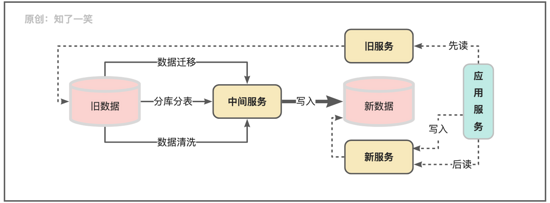
微服务架构下数据的动态维护是一个比较复杂的流程,要保证在处理过程中不停机,需要依赖中间的调度服务去完成数据的维护过程,在此期间应用服务优先从旧服务和库中读取未处理的数据,新数据入库和查询走新的服务,直到整个维护流程结束,再根据预设好的标识关闭旧服务请求并且下线即可;
五、缓存管理
通常缓存可以有效解决数据查询时出现的性能问题,比如访问量大变动不频繁的热点数据,或者流程中经常加载的常量配置,另外也会基于Redis做加锁机制,一般采用键值对的方式管理数据读写;
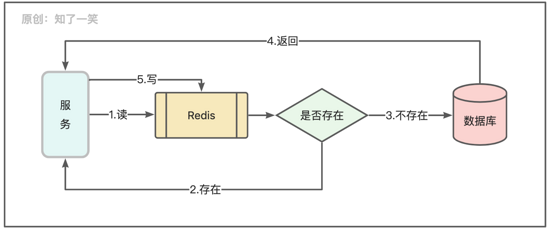
值得注意的是,通常Redis库与业务库是具有一定的对应关系,例如订单业务库对应订单缓存库,并且不建议订单业务库数据主体被写入其他缓存中,统一通过订单服务的接口访问即可,保证各个微服务的数据独立性;
六、搜索引擎
当业务量大的时候,很难执行数据整体的条件检索机制,比如常见的核心业务数据、系统产生的日志或者动作埋点数据;需要引入搜索引擎的能力,这就涉及到业务库数据向ElasticSearch组件同步的过程;
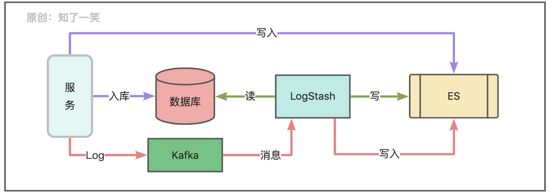
不同的业务场景中,通常采用不同的数据同步策略;针对即时性高的业务数据,通常数据入库后执行写入;日志数据量大且流程解耦较高,自然存在一定的延时;分析类的数据则基于定时任务拉取即可;不管什么数据路径,都要重点关注业务库和索引之间的数据结构和一致性问题;
七、消息队列
消息队列作为流程解耦的常用组件,对消息数据的生产和消费需要一定的监控手段,复杂的流程一旦中断,需要进行二次重试的话,则需要调度各种参数和消息内容结构,来保证流程的最终完整性;
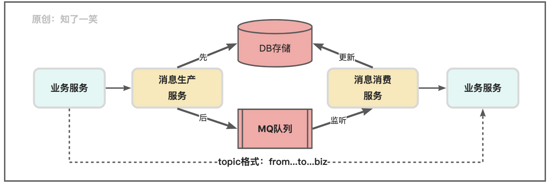
通常来说消息队列处理的业务复杂性都很高,所以比较考验流程设计的合理性,如果不统一管理消息的生产和消费的路径,在微服务的架构下基于MQ做流程的分段解耦,如果出现流程中断或者系统异常的情况,都很难对相关逻辑做二次调度;
八、日志信息
日志作为系统中的基础组件,记录的相关数据在日常开发维护的过程中十分重要,从数据的整体来看大致分为系统运行日志,通常基于ELK的方式,另外就是业务日志,需要具备业务语义,通常采用AOP切面模式进行定制开发;
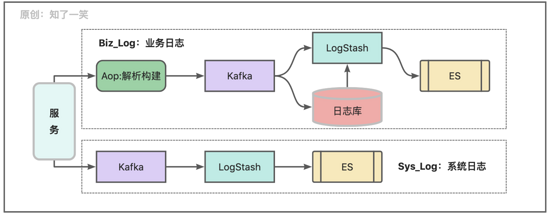
由于日志数据的体量很大,业务日志一般会存放在单独的库内,并且同步到搜索引擎中,对于系统运行日志则按照时段或者文件大小的策略直接写入搜索引擎;值得注意的是存放日志数据的ES也需要独立部署,避免与核心的业务数据放在一起,当流量突然增长时产生的日志数据会非常大;
九、文件管理
文件管理是系统中的复杂模块,由于涉及IO流很容易引发内存问题,所以文件服务基本都会独立部署,鉴于文件数据丢失很难找回的情况,通常会把文件存储到OSS云端,在文件服务中会记录各个文件的地址和描述以及业务应用场景;
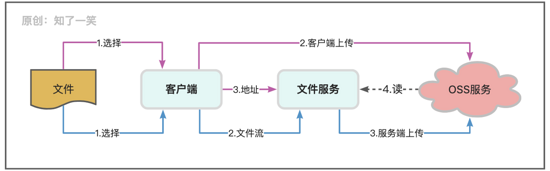
由于文件的类型多种多样,比如:PDF、Excel、Word、Csv、Xml等等,其数据处理的手段也各不相同,如果文件过大还需要切割分块,同时文件管理的过程需要很多约定的规则,比较常见的就是大小限制,命名信息,类型与编码等;
十、持续集成
代码工程在版本的交付中,会产生多个分支和打包文件,持续集成的过程也涉及多个文件仓库的维护管理,比如:Git代码仓库、Maven私有制品仓库、Docker镜像仓库、脚本文件仓库等;通过Jenkins服务协调多个仓库实现流程自动化;
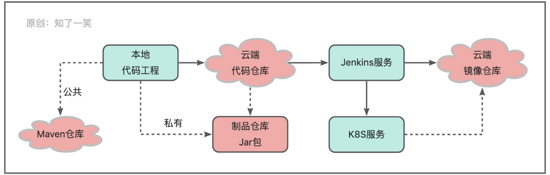
对于仓库存储的各种版本打包文件,微服务架构下存在不同服务依赖同一服务不同版本的情况,另外不排除新老版本的接口存在逻辑冲突问题,此时可能需要版本回滚,重新依赖原有的分支包,再寻求问题的解决方案;关于代码工程涉及的相关存储基本都是使用第三方的云端仓库,在管理维护方面比较简单;
十一、参考源码


