
服务器性能问题,通常在数据少的时候不会显现,也无需太多关注。但一旦数据量大了,就会变成一个麻烦且必须处理的事。
通常,性能问题可能有许多不同的原因。内存问题、缓慢的数据库请求和太少的机器只是其中的一部分。手上的项目,每天10亿级的数量量,在最近一个时间段,填了很多坑,也学到了不少东西。
今天这个文章,我会把这一段的体会,总结成几大类问题。当然,分类不一定很严谨,重要的是能给到大家一些建议,真到用时,能少刨一些坑,就够了。另外,次序也不重要,我是想到哪些到哪的,并不是说前边的内容就比后面的内容更需要注意。
1. 数据库调用
数据库调用的性能,会严重影响系统整体的性能。大多数情况下,与数据库快速交互是获得良好性能的最重要的因素。
以下几个点需要重点关注:
- 索引策略
索引对数据库交互的影响不需要解释。重要的是检查,检查每一个索引,和每一个查询语句。很多时候,你以为的未必是你以为的。检查查询语句和条件对索引的使用,检查索引的结构。要确保每个查询语句,能正确使用你所希望使用的索引。
- 表结构设计
表结构设计最重要的,是对业务的理解。对数据之间的关系理解越深,表结构越趋于合理。
- 同样的工作,尽可能在数据库上完成,避免在服务器中完成
这个话不太好理解,用代码举个例子:
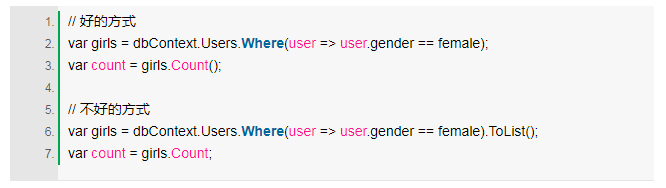
下边这种方式,第一行以ToList()结束。当实体执行查询时,会从数据库中检索并获取全部数据,然后在服务器中进行计数。而上面的方式,会在数据库中直接计数。很显而易见的,数据库中执行计数,网络传输的代价会更少。
- 尽可能让数据库离应用服务器"近"点
数据库到应用服务器之间,无非是网络。更"近"的网络,会带来更少的延时。这个"近"说的是网络拓扑上的近,不是位置和距离。对于多机房分布式的应用,起码的要求是让一个或几个完整的副本集与应用服务处于同一个数据中心。
- 用数据库希望的方式使用数据库
数据库有很多种,关系型、NoSQL、内存数据库,等等。并不是所有的数据库都一样。有些适合Key-Value键值对,有些适合事务处理,有些适合存储日志。
在开发中,不要拘泥于数据库类型,而应该根据业务类型和数据库特性进行使用。比方说,MongoDB,本身是基于文档的数据库,结构上很不适合JOIN操作。但它非常适合存储包含大量业务数据的文档。所以,使用时要避免使用JOIN操作的业务。当然,这只是个例子。事实上MongoDB对于类似JOIN的内容,有更好的处理模式,这个大家可以自行了解。
- 保证数据库有足够的硬件资源
服务器的伸缩一般提的比较高,但其实数据库的伸缩性也需要非常重视。数据库服务器,要关注到存储空间、内存、网络和CPU。经验中,接近极限时,服务器未必会有明确的警报给你;而等到有警报出现时,恐怕已经到达极限并发生了故障,就非常难于处理了。
所以,当发现某些任务开始变慢,就意味着需要全面检查了。
- 承认某些低效查询的存在
不是所有的查询都可以做到高效。尤其查询是基于某些实体框架,例如EF或Hibernate。在技术和时间可能的情况下,少用数据框架是个好习惯。
- 使用连接池,而不是单个连接
如果每个查询都需要重新建立连接,那是非常可怕的,从性能到应用的可靠性。使用数据库,第一件事就是学会如何使用连接池。
- 小心使用存储过程
当有需要花费大量时间的复杂查询需要处理时,存储过程是个解决方案。但一定要小心,一定要小心,一定要小心,重要的事情说三遍。
在我的团队中,存储过程是被禁止使用的。相对来说,这儿安全的要求超过性能。
不过,在这个文章中,尤其在讨论数据库操作的性能时,咱还是不能忘了存储过程。
- 数据库分片策略
分布式数据库性能的核心在于分片。分片就一个原则:让业务的每一个查询操作,对应尽可能少的分片。
上面写的,其实是一些原则。实际上,最难的部分是确定这些问题。所以,需要对各种工具都熟悉。通常,数据库本身也能提供相关内容,例如慢查询、扩展问题、网络瓶颈等。对于数据库,不要仅限于使用,一定深度的了解会对成长有相当的帮助。
2. 内存压力
对于某些高吞吐量的应用,服务器的内存压力是最常见的问题。
当吞吐量非常大的时候,垃圾回收(GC)会跟不上内存的分配和释放。而且这种压力的体现,是服务器在垃圾回收上花费的时间更多,而执行代码的时间更少。
这种状态在多种情况下都可能发生。最常见的情况是内存容量耗尽。当您达到内存极限时,垃圾回收器将出现恐慌,并启动更频繁的整体垃圾回收,而这种模式的回收代价非常大。但问题是,为什么会发生这种情况?为什么你内存使用接近极限了?原因通常是错误或不太好的缓存管理或内存泄漏。通过捕获内存快照并检查是什么占用了所有字节,可以很容易地用内存分析器发现这一点。
重要的是首先要意识到你有内存问题。最简单的方法是使用性能计数器。
3. 缓存数据
缓存可以是一个非常好、非常有效的优化技术。典型的例子是,当客户端发送请求时,服务器可以将结果保存在缓存中。当客户端再次发送相同的请求(不一定是同一个客户端)时,服务器不需要再次查询数据库或进行任何计算来获得结果,而只是从缓存中获取它。
考虑一下搜索引擎的做法。如果这是一个常见的搜索,它可能会被要求每天多次。如果不做缓存,每次都使用计算力去生成相同的页面,是不是很可怕?
当然,使用缓存,在一定程序上增加了应用的复杂性。首先,每隔一段时间就需要使缓存失效并刷新,对吧?我们总不可能永远返回相同的结果。另一个问题是,如果使用不合理,缓存容易膨胀,并导致内存问题。
好在,ASP.Net有很多已经实现的优秀的缓存库可以帮助解决大部分的工作。
4. 垃圾回收优化
应用服务器性能优化中,垃圾回收是一个必须考虑的问题。
我们知道,Dotnet垃圾回收有两种不同的模式:工作站模式和服务器模式。前者被优化为以最小的资源使用快速响应,而后者用于高吞吐量。
Dotnet运行时默认将桌面应用程序中的GC模式设置为工作站模式,而服务器中的GC模式设置为服务器模式。这个默认值几乎总是最好的。在服务器中,GC将使用更多的机器资源,但是能够处理更大的吞吐量。换句话说,该进程将有更多的线程专门用于垃圾回收,它将能够每秒释放更多字节。
相比由系统自动默认GC模式而言,手动设置应用的垃圾回收模式会是一个安全的做法。服务器并不是总能正确地意识到需要什么样的回收模式。
5. 减少不必要的客户端请求
客户端请求的数量,很大程度上可以决定服务器的数量或服务器的负载。所以,通过一些技巧来减少服务器请求,也是优化的一部分内容。
这个内容需要在应用中具体探讨或体会。我只举几个实用的例子:
- 自动完成机制
通常这种应用,就是我们在前端输入时,客户端从第一个输入字符开始做API调用。比方我们输入"Dotnet",那我们会向服务器发送6个请求 --- "D"、"Do"、"Dot"、"Dotn"等等。但实际上,考虑到输入的连续性,我们可以在调用前,做个短时的延时,比方停止输入500ms后才向服务器发送请求。你可能不会相信,我们实际应用中实测的结果,可以减少93%的调用。
- 客户端缓存
还是上面的例子。对于同一个应用,很多位置的输入都是相同或类似的。如果我们将自动完成的结果缓存在客户端,而不是每次都发送这些请求,同样可以减少很多不必要的请求。
- 批处理
应用中,一个页面跟服务器的交互通常会有很多。通常最无脑的做法,就是一个事件发送一个请求。这样的方式无形中会对服务器产生相当的压力。如果可能,把这样的事件合并成一个请求,会更有效率,对服务器更友好。
6. 正确处理挂起的请求
客户端对服务器的请求,可能会被挂起。也就是说,客户端发送了一个请求,但未收到响应,或者准确地说,是经过一个比较长的时间后,收到一个超时响应。虽然我们不希望发生这样的事,但这种事情总在发生:处理请求时间过长、或代码死锁、或代码出错并且没有正常捕获错误,当然还包括等待一些本应该出现但实际未出现的东西,例如来自队列的消息、长时间的数据库响应或对另一个服务的调用。
本质上,当一个请求被挂起时,会挂起一个或多个线程。但应用程序并不会停,并继续处理新的请求。如果这个挂起在其它请求上也有重现,那随着时间,挂起的线程将越来越多,并最终影响服务器或系统的响应。
因此,请求挂起对服务器性能的影响非常大。
这个问题的解决,需要针对核心的部分,就是挂起的部分进行调试,以确保程序处理了各种可能性,并不会产生任何意外的挂起。
7. 服务器崩溃
服务器崩溃也是一个可能的性能问题。
通常来说,客户端请求期间发生一般的异常时,应用程序不会崩溃。但总有一些问题,比方上下文之外的异常,或者一些灾难性的异常,比方OutOfMemoryException、ExecutionEngineException、StackOverflowException,当这些发生时,不管加多少catch,也挡不住崩溃的发生。
通常如果的托管在Web Server上,例如:IIS、Nginx、Jexus上的ASP.Net应用,崩溃时Web Server会自动回收资源,并重启应用。客户端的感觉是临时的慢响应或503错误。
而如果是直接启动的ASP.Net应用,则程序会永久关闭,需要手动重启。这将是一个问题。
所以,一方面,使用Web Server会是一个好习惯。另一方面,还是要检查代码,从根本上解决问题。
8. 永远记着应用规模
这个问题说起来很简单,但实际开发中,其实经常会忘记,或者说忽略应用的规模。
用缓存,会忘了分布式缓存,忘了同步问题,直接使用单机内存缓存;
数据库写入,会忘了并发下的数据一致性问题;
。。。太多了,不一一写了
解决的办法,是从头开始,就把代码规模化 --- 从开发到测试,全部使用双向扩展,即水平扩展(向外扩展)和垂直扩展(向上扩展)。垂直扩展意味着服务机器添加更多的功能,比如更多的CPU和RAM,而水平扩展意味着添加更多的机器。
记着,从开发和测试开始,就要使用与生产环境使用同等规模的环境来做。
9. 同步和异步
应用服务不同于桌面应用或终端应用。当服务在执行过程中需要等待响应时,比方数据库操作、或者调用别的服务时,这个服务本身就开始有了一定的风险。如果数据库或别的服务正忙着处理别的请求、或者存在性能问题时,必然会把性能问题传递到调用方。
怎么办?
解决的基本模式是异步调用。异步调用有两个含义:
- 代码的异步调用,就是我们常说的async和await。
- 架构的异步调用。这个通常是通过使用Kafka或RabbitMQ这样的队列服务来完成。向队列发送消息,并不等待响应。由另一个服务提取这些消息并处理。这个方式,通常是不需要回复的服务。而如果需要回复,也可以用类似SignalR这样的推送通知。
重要的是,这样的方式下,系统组件不需要主动等待服务。一切都是异步处理的。服务之间的耦合可以松散很多。
当然同样的,这样会让代码变得更复杂。
取舍之间,是对代码的控制力。
10. 一个小总结
出差期间,断断续续写的这个东西,似乎有点乱,但就这样吧,:P
在实际项目中,很多方面稍不注意,就能搞乱服务器的性能,而且有很多地方会出错。而解决呢,又没有捷径和技巧,需要仔细的计划,有经验的工程师,以及大量的缓冲时间来应对可能出现的问题。
后面我写写一些工具的应用吧。很多方面,还是有好的工具可以帮助解决或至少是快速发现问题的。
总之,这是一篇个人的经验之谈,希望能给大家一个抛砖引玉的作用。

