
1. 抢跑的nlp
nlp发展的历史非常早,因为人从计算机发明开始,就有对语言处理的需求。各种字符串算法都贯穿于计算机的发展历史中。伟大的乔姆斯基提出了生成文法,人类拥有的处理语言的最基本框架,自动机(正则表达式),随机上下文无关分析树,字符串匹配算法KMP,动态规划。
nlp任务里如文本分类,成熟的非常早,如垃圾邮件分类等,用朴素贝叶斯就能有不错的效果。20年前通过纯统计和规则都可以做机器翻译了。相比,在cv领域,那时候mnist分类还没搞好呢。
90年代,信息检索的发展提出BM25等一系列文本匹配算法,Google等搜索引擎的发展将nlp推向了高峰。相比CV领域暗淡的一些。
2. 特征抽取困难的cv
cv的前身就有一个领域叫图像处理,研究图片的压缩、滤波、边缘提取,天天摆弄着一个叫lenna的美女。

早期的计算机视觉领域受困于特征提取的困难,无论是HOG还是各种手工特征提取,都没办法取得非常好的效果。
大规模商业化应用比较困难。而同期nlp里手工特征➕svm已经搞的风生水起了。
3. 深度学习的崛起- 自动特征提取
近些年,非常火爆的深度学习模型简单可以概括为:
深度学习 = 特征提取器➕分类器
一下子解决cv难于手工提取特征的难题,所以给cv带来了爆发性的进展。深度学习的思路就是让模型自动从数据中学习特征提取,从而生成了很多人工很难提取的特征:
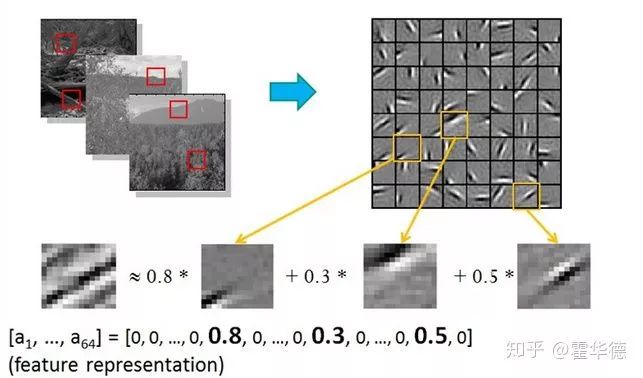
4. nlp的知识困境
不是说nlp在这波深度学习浪潮下没有进展,而是说突破并没有cv那么巨大。很多文本分类任务,你用一个巨复杂的双向LTSM的效果,不见得比好好做手工feature + svm好多少,而svm速度快、小巧、不需要大量数据、不需要gpu,很多场景真不见得深度学习的模型就比svm、gbdt等传统模型就好用。
而nlp更大的难题在于知识困境。不同于cv的感知智能,nlp是认知智能,认知就必然涉及到知识的问题,而知识却又是最离散最难于表示的。

