根据麦肯锡的数据,从现在到2030年这十几年间,人工智能将会为美国新创造大约13万亿美元的国内生产总值。相比之下,2017年整个美国的国内生产总值约为19万亿美元。
吴恩达等主要的人工智能科学家将人工智能描述为第四次工业革命或“新电力”。人工智能无疑是数字转型的核心,它在整个行业的应用将极大地改变世界和业务方式。
许多人想参加这场人工智能革命,但人工智能的技术复杂性使他们不堪重负。他们不知道人工智能的功能,更不用说如何将人工智能运用于公司了。
这正是本文所要解决的问题:让没有技术背景的人更理解人工智能,这样他们自己就能够评估人工智能在自己工作中的可能性。

1. 对人工智能的误解
人工智能有很多不必要的炒作,这主要是由于许多人都有一种常见的误解。人工智能可以分为两部分或存在两种内容:
(1) 弱人工智能(ANI)
这指人工智能擅长某一特定任务,它们是针对这一任务训练和开发的。例如,它可以是一个基于历史数据预测房价的人工智能系统,或者是向你推荐YouTube视频的算法。还比如是预测性维护、质量控制等。
弱人工智能是一个非常强大的工具,它将在未来几年为社会增加许多附加价值。近年来看到的所有成就,以及在新闻中经常听到的内容,都发生在弱人工智能领域。这些吸引人眼球的新闻让人们错误地认为科学在人工综合智能方面取得了很大的进展,但实际上只在弱人工智能方面取得了进步。
(2) 通用人工智能(AGI)
人工智能的最终目标是一个跟人类一样只能甚至比人类更智能的计算机系统。任一人工综合智能都可成功地完成任何人可以完成的智力任务。这也是人工智能中最引起人们恐惧的部分。他们想象出一个计算机比人类聪明得多的世界,在这个世界里几乎每一项工作都是自动化的,甚至是像《终结者》一样的场景。这就是不必要的炒作。它引起了对人类未来的非理性恐惧,而实际上,要想达到真正的通用人工综智能水平,还需作出许多技术上的突破。
2. 什么是机器学习?
机器学习是人工智能的中坚技术。它利用统计技术使计算机程序能够从数据中学习(例如逐步提高其处理特定任务中的能力),而无需进行明确的编程。
机器学习是人工智能的工具,它引起了所有的过度关注,并使几乎所有通过人工智能系统创造的价值都得以实现。它也可以分为不同的部分,但只有一个部分涵盖80%通过机器学习创造的价值。那便是有监督学习。
有监督学习算法只需通过学习大量数据中的关系来学习输入(A)到输出(B)映射。想象一下建立一个系统,将电子邮件分为垃圾邮件和非垃圾邮件。需要收集大量电子邮件“被贴标签”的案例。这意味着每封电子邮件都有一个标签用来指示它是否是垃圾邮件。人们需要收集数千封带有标签的电子邮件,然后将这些数据输入到一个受监督的机器学习算法中。
在训练过程中,该算法将分析所有输入的电子邮件,并迭代地提高对垃圾邮件与非垃圾邮件间区别原因的理解。在本例中,系统必须将电子邮件(a)映射到一个标签,该标签要能指示邮件是否是垃圾邮件(b)。
可以通过输入上千封贴有标签的电子邮件来训练算法。基于该数据进行算法训练后,可以输入一封全新的电子邮件(该算法以前从未见过),该算法将显示它是否认为该电子邮件是垃圾邮件。
比如在线广告,其中输入的是关于用户的信息(A),而系统输出是一个标签,这个标签显示用户是否要单击一个添加项(B)。又比如是语音识别,输入是音频文件(A),输出是音频文件中所述内容文本(B)。
再比如输入一个钢板的图像(A)进算法,它会判断是否存在缺陷(B)。乍一看,这似乎是一种相当有限的技术,但如果正确应用,它将非常强大。它是人工智能为社会创造附加价值的唯一主要原因。这种技术似乎有无穷无尽的不同案例,并且人们每天还会发现新的案例。
3. 人工智能术语

人工智能是一个非常复杂的领域,许多术语在开始时可能会使人非常混乱。你可能听说过神经网络、深度学习或数据科学。我们将研究一些有关人工智能最重要的术语,并揭示其含义,以便你能够与其他人讨论人工智能,并思考如何在业务中应用人工智能。
现在为你提供最常用的人工智能术语的定义,但请注意,人工智能是一个非常晦涩难懂的领域,许多术语可以互换使用,但有时却不可以。
(1) 人工智能
人工智能是计算机科学的一个领域,它强调创造像人类一样工作和反应的智能机器。正如之前所提到的,当人们谈论人工智能时,他们大多是指通用人工智能(AGI)。应该把人工智能视为整个智能领域,把机器学习和深度学习视为使计算机智能化的技术。
(2) 机器学习
机器学习是人工智能的一个分支领域。不过,正是这个研究领域使计算机能够在没有明确编程的情况下从数据中学习。因此,通过机器学习,基本上可以制作程序来执行特定任务。因此,机器学习经常会运行人工智能系统,从基本上来看,这个系统是一个软件。
机器学习项目事例:假设一家有许多关于房子的数据的房地产公司,它和一家机器学习公司合作建立一个机器学习系统来预测未来房价。这样的系统可以让人更好地决定投资哪栋房子,并找出合适的时间来清算投资。
(3) 深度学习
深度学习是机器学习的一个组成部分,它包揽了人们近年来看到的,并且今天仍然看到的,所有的媒体炒作和人工狭义智能的大部分突破,这与机器学习基本上是一样的:给算法贴上带有标签的数据,它就会学会预测标签。与机器学习不同的是,深度学习使用了更现代和更复杂的算法,称为神经网络。相反,在机器学习中使用的则是更为简单的传统算法。
由于它们的复杂性,新的技术发现以及足够的数据支持和计算能力,深度学习算法能够打破许多任务的先前基准,甚至在其中一些任务上超过人类(例如:组织病理学图像分析,或者在Netflix上推荐电影)。
尽管神经网络(例如深度学习算法)几乎总是比传统算法表现更好,但它们具有某些缺点。
更多信息传送门:神经网络的优缺点(https://towardsdatascience.com/hype-disadvantages-of-neural-networks-6af04904ba5b)
你可能经常听说神经网络的构建方式与人类大脑相似或受其启发,但实际上,它们几乎没有关系。的确,它们最初受到大脑的启发,但工作方式的细节与人类生物大脑的工作方式完全无关。
请注意,许多人可以互换地使用深度学习和神经网络这两个术语。
深度学习项目示例:高级视图中审视它时,深度学习的项目与机器学习项目没有太大差别,只需要更多数据,更多计算能力和高技能工程师。
(4) 数据科学
数据科学项目的输出通常是一系列可帮助你做出更好的业务决策的见解,例如决定是否投资某些东西,是否应该购买某些设备,或者是否应重新构建你的网站。可以说,数据科学是通过统计方法、可视化等分析数据来提取数据知识和洞察力的科学。输出通常是演示文稿或幻灯片,它们为高管、领导者和产品团队做出某些决总结结论,以作出某些决策。
数据科学项目示例:
想象一下,你从事在线广告业。通过分析所在公司的销售数据,数据科学家发现旅游行业的公司不会从你那里购买很多产品。因此,你可以将销售团队的重心转移到旅游行业的公司。
另一个例子:
想象一下,你正在经营电子商务,并且聘请了一些数据科学家以获得更多与业务相关的见解。该项目的结果可能是一个幻灯片,介绍如何修改定价的计划,以便提高整体销售额或关于如何更有效地营销特定产品的见解。
有人说人工智能是数据科学的一个子集,有些人说它是另一种方式。所以,这取决于你与谁交谈,但数据科学是一个跨学科领域,涉及人工智能、机器学习和深度学习的许多工的,但它也有自己独立的工具。其目标主要是提升商业洞察力。
你可能还听说过其他流行语,如强化学习、生成对抗网络(GANs)等。这些只是使人工智能系统更智能化的其他工具,换句话说,机器学习有时也是数据科学。
现在已经了解了人工智能、机器学习、数据科学和深度学习(例如神经网络)。希望这能让你了解人工智能中最常用的术语,并且可以开始考虑这些事情如何应用到业务当中。
4. 什么是数据?
数据可以采用多种形式:电子表格、图像、音频、传感器数据等。这些可分为两大类:结构化和非结构化数据。
(1) 结构化数据(“生活在巨型电子表格中的数据”)
结构化数据,就像它的名称所暗示的那样,是按照预定义模式以结构化格式存储的数据。它指的是驻留在记录或文件中的固定字段中的任何数据,可以是文本的也可以是非文本的。
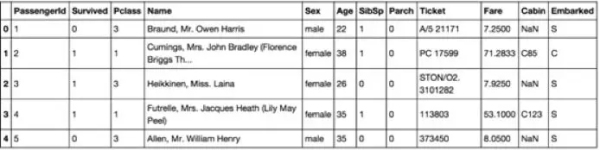
下面是著名的泰坦尼克号数据集中的结构化数据示例。它包含坦尼克号每位乘客的信息。
(2) 非结构化数据
非结构化数据本质上是未通过预定义模型构建的其他所有内容。它可以是文本的或非文本的,但当人们谈论非结构化数据时,它们主要是指图像、视频、音频文件、文档等。
我们已经解释了什么是监督学习。由于监督学习是最常用的机器学习类型,当人们说“数据”时,它们主要是指标记数据。示例:有一个数据集,其中包含100,000只狗和猫的照片,其中每张照片都有一个标签,“猫”或者“狗”。
另一个例子是包含房价信息的数据集。在这里,你将获得有关房屋的信息(如面积,卧室数量,位置等)以及作为标签的价格。
5. 如何获得数据?
可以在互联网上找到许多问题的数据集(一些是免费的,一些要花点钱),但大多数时候需要创建自己的数据集。
获取数据有三种主要方式:
(1) 手动标签
想象一下建立一个分类器,可以检测给定图片上是否有男人或女人。要训练这样的分类器,需要创造或获得许多男女形象。然后,你需要为每个图像指定一个标签:男人(标签1)或女人(标签2)。你也可以向人们付费为你做标签工作(例如:亚马逊机械土耳其人:mturk.com)。
(2) 观察行为
想象一下,你在经营一家电子商务公司并希望预测客户何时会进行购买,从而使你能够更好地管理股票等。你可以通过观察用户在网站上的行为以及购买情况来创建数据集。这将有助于创建描述每个用户的操作的数据集(由某些变量描述,例如:一天中的时间,他们点击的位置等),以及标签:购买(标签1)或不购买(标签2)。
另一个例子是观察机器的行为,这可以使你预测它何时需要维护等。
(3) 使用免费数据源,购买数据或从合作伙伴处获取数据
像Kaggle这样的数据集有许多免费资源。还可以使用Google数据搜索,其功能类似于Google,但仅适用于数据集。如果没有找到任何内容,可以在数据市场上查找数据集或从合作伙伴处获取数据集。
6. 滥用数据
乍一看,获取数据似乎很简单,但可能出现的问题很多。在人工智能和机器学习中,我们说:“垃圾中的垃圾”,这意味着你在培训期间将人工智能质量从人工智能系统中提取出来。
想象一下,你想创建一个特定的人工智能应用程序并开始获取数据。你的计划是用两年实践累积数据,然后构建人工智能系统。这是非常糟糕的做法。在这种情况下,正确的方法是获取你能够获得的数据并尽快将其提供给人工智能专家。经过一些评估后,他可以告诉你,哪些部分是有用的,哪些部分是完全无用的,以及你应该添加哪些数据。为了节省金钱和时间:与专家一起快速评估数据质量。
另一个大问题是标签不正确。示例:猫的形象标记成狗而狗被标记成猫等等。这可以防止你的算法学习真正将猫与狗分开的东西然后完全混淆它们。好消息是,数据总数越多,标签不正确的问题就变得越来越不重要了。如果你有一个巨大的数据集,有超过200万个标记的猫和狗图像,一些不正确的标签不会影响其性能。
还有一个问题,有些人认为,因为他们的公司拥有大量数据,并且这些数据很有用,或者人工智能团队可以让它们变得有用。那完全错了。虽然更多的数据通常更好,但你可以拥有数十亿的数据条目,即使是世界上最好的人工智能工程师也无法从没有价值的东西中创造价值。因此,请不要把数据丢给人工智能团队,并假设它在某种程度上是有价值的。你可能认为这很稀松平常,但由于对数据和AI的误解,很多创业公司认为他们拥有有用的数据,而事实上他们没有。还有其他问题是价值缺失,多种类型的数据(可以解决 - 但成本高昂)等等。

