本文转载自公众号“读芯术”(ID:AI_Discovery)。
“互联网上有很多数据”,这么说太保守了。事实上,2020年,“数字宇宙”预计将拥有40万亿字节或40泽字节(zettabytes)的信息,一个泽字节拥有的数据足以填满大约五分之一曼哈顿大小的数据中心。
可供分析的信息如此之多,将收集数据的任务留给AI就显得合情合理了。网络机器人能以令人难以置信的速度抓取网页,提取所需的相关信息。不过,尽管许多数据科学家和营销人员以一种完全合乎伦理的方式获取和使用这些信息。但很遗憾,随着网络人工智能日益普及,网络机器人还是逐渐被污名化了。

对人工智能的大部分负面印象是由好莱坞电影和科幻小说间接造成的,毕竟在这些作品中,即使最美好惬意的时候也要提防着AI。此外,某些web用户以不道德的方式使用网络机器人,导致即便是专业、诚心使用数据的人也备受打击。
对于许多专业人士来说,网页抓取仍然是必不可少的工具。那么,对于与网络机器人的污名,我们能做些什么呢?
首先,网页抓取是什么
你可以简单地把网页抓取行为理解为数据提取。尽管数据科学家和其他专业人士使用抓取来分析非常复杂的数字信息栈,但从网站复制粘贴文本的行为本身就可以被认作一种简单的抓取形式。
然而,就算可以在网站上尽情访问,由于可用信息太多,可能也要花费非常长的时间从来源处收集数据。大多数情况下,网页抓取都是留给人工智能来完成的,人工智能会将检索到的数据进行透彻分析以达到各种目的。虽然这对网络爬虫来说极为便利,但网站所有者和旁观者都非常担心人工智能在网络上的“滥用”
使用网络机器人进行网页抓取会更好吗
有这么多的信息要分析,求助于人工智能来收集数据理所当然。实际上,谷歌本身就是为感兴趣的各方提供网页抓取工具最可信的来源之一。例如,你可以使用其数据集搜索引擎快速访问认为可以免费使用的数据,甚至能定制搜索,以了解这些信息是否可用于商业用途。完成这些任务只需要几秒钟。
如果没有谷歌AI如此高效检查每个网站的相关数据,恐怕无法实现这样的速度。这是一个利用人工智能以纯道德的方式为研究或商业收集有用信息的完美例子,其速度之快也证明了“网络机器人”如何让执行网页抓取任务变得如此容易。
人工智能流量变得如此普遍,如今已经占到互联网流量的一半以上。即便如此,我们还是容易忽视其造成的影响。
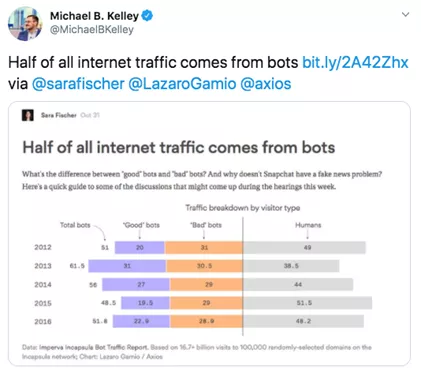
机器人程序流量报
有人认为,人工智能在互联网流量中占主导地位令人担忧。让这一问题变得更糟的原因是,有一小部分人工智能流量是由“糟糕的机器人”组成的。即使抓取的意图很好,方法也合乎道德,人工智能的污名还是不可避免。
使用网络机器人来处理大量数据是合理的步骤。除了人工智能,在网页数据抓取时考虑其他必要工具也很重要。
代理如何提供帮助
使用代理进行网络抓取有很多优点,匿名性正是其中之一。比方说,如果你想对一个竞争品牌进行调研,并利用这些信息来确定改善自己公司发展的最佳方案,你可能不想让别人知道自己访问了他们的网站。在这种情况下,使用代理既能访问、检查数据,又不会泄露身份,两全其美。
做进一步探讨之前,先来快速回顾一下代理服务器:
- 代理服务器的设计目的是充当用户和web服务器之间的中间人。
- 功能多样:个人和公司都能使用代理服务器来满足特定需求。
- 代理的一个常见用途与网页抓取有关:使用代理服务器可以绕过网站管理员设置的限制,从而大量收集数据。
那么问题来了,为什么要设置限制呢?这些数据不是可以在网上免费获得吗?对人类用户来说,是的。这里有一个典型的例子。价格聚合商的整个商业模式是建立在准确信息之上的,它为“我在哪里能买到价格最低的X产品?”这个问题提供确切答案。
尽管这对客户来说是一个省钱的好机会,但供应商对其他公司窥探他们的数据并不太感兴趣,原因是聚合器的网络爬虫软件(通常称为“网络机器人”或“网页蜘蛛”)给网站带来了额外的负载。因此,如果网站管理员怀疑给定的网络活动不是由真正的用户进行的,就会限制用户访问网站。
代理的另一个实际用途是逃避审查禁令。住宅代理(Residentialproxies),顾名思义,会显示你是来自X国的真正用户,你可自定义来自哪个国家。对住宅代理的需求很简单:(可疑的)网络机器人活动通常来自某些国家,所以即使是来自这些国家的真正用户也经常遇到地域限制。
此外,当你试图从数据源收集数据、却因各种原因无法访问时,使用代理尤其有用。在网络抓取时有很多使用代理的方法,但为了在数字社区中建立信任,我们建议你坚持使用那些可以建立品牌信任和权威的方法。

图源:unsplash
利用人类可见性和可信赖的品牌来对抗人工智能的污名
目前,人工智能发展速度确实超过了上网人数增长速度。不过,互联网在未来几年将会如何发展还不得而知,因此没有理由立即断定这一趋势不可逆转,也不能断定它代表着一种固有的消极趋势。
要想扭转网络上有关人工智能流量的负面言论,最佳办法就是让互联网上的人工智能使用恢复人性化。还需注意,要以建立信任的方式使用人工智能,无需考虑太多。
- 坚持使用由高认知度、可信赖的品牌提供的可信赖的产品和服务。
- 坚持合乎道德的网页抓取操作。不要滥用信任,忽略网站上robots.txt文件,或在短时间内大量使用机器人程序。
- 以专业、负责的方式使用数据。核实你是否拥有将抓取获得的数据用于预期目的的权限。
- 多多普及人工智能。多去和其他人说说如何以及为什么使用网络抓取,让人们对网络抓取有更深的认识。人们对使用人工智能获取、研究大量数据的好处了解得越多,对网页抓取和网络机器人持负面看法的可能性就越小。
通过纯粹的人工操作来手动访问网站数据或许让人很放心,但由于信息太多,这几乎不可能。可用的数据量几乎无穷无尽,使用人工智能是我们浏览网站和尽可能高效分析数据的最佳手段。不过,它或许还需要再加点儿“人情味”。


