译者 | 崔皓
审校 | 重楼
摘要
本文强调MLOps(机器学习运营)的重要性,并详细介绍了其五个关键阶段:问题框架、解决方案框架、数据准备、模型构建和分析以及模型服务和监控。文章通过一个金融科技案例研究,详细解释了如何在实践中应用这五个阶段。最后,文章强调了实施MLOps的好处,包括解决业务问题、使用正确的工具、善用代表问题的数据集、构建最优的机器学习模型,以及部署和监控模型。
开篇
许多数据科学项目因为各种原因都不为人所知。MLOps就是其中一个, MLOps指的是从数据阶段到部署阶段的过程,它可以确保机器学习模型的成功。在这篇文章中,你将了解到MLOps的关键阶段(从数据科学家的角度)以及一些常见的陷阱。
小贴士:MLOps市场在2019年估计为232亿美元,并预计到2025年将达到1260亿美元,原因是MLOps被业内广泛应用。
MLOps的动机
MLOps是一种专注于运营数据科学模型的实践。通常,在大多数企业中,数据科学家负责建模数据集,预处理数据,进行特征工程,最后构建模型。然后,模型被“扔”给工程团队,以便部署成API或者站点。在这个过程中,科学(建模)和工程(部署)往往在各自的孤岛中进行,两部分工作的隔离导致部署延迟,在最坏的情况下,会导致部署错误。MLOps可以快速准确地部署企业规模的ML模型。数据科学往往被人认为 “说起来容易做起来难”。MLOps就是这一领域的灵丹妙药,用来根治从模型学习到生产部署的各种疑难杂症。其实数据科学家都清楚,90%的ML模型并没有投入生产。MLOps给数据科学和工程团队带来了标准和流程,确保他们紧密且持续地合作。这种合作对于确保模型成功部署至关重要。
简述MLOps
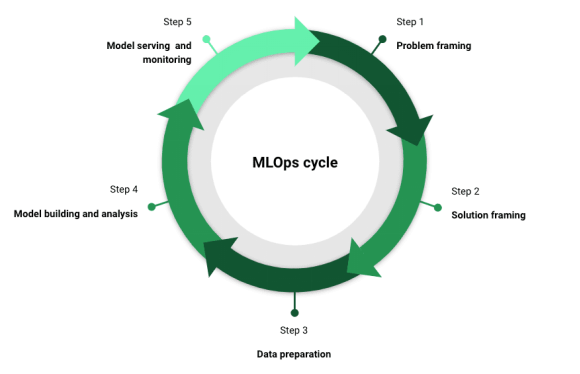
对于熟悉DevOps的人来说,MLOps对于机器学习应用就像DevOps对于软件应用一样重要。MLOps有多种形式,然而有五个关键阶段对于MLOps策略至关重要,同时每个阶段都需要与利益相关者进行沟通。下面我们就展开说明有哪五个阶段:
问题框架
深入理解业务问题。这是成功部署模型和使用的关键。在这个阶段需要与所有的利益相关者进行交流,从而获得项目的支持。包括工程、产品、合规等。
解决方案框架
只有在问题陈述被详细讨论之后,才开始考虑“如何”以及是否需要机器学习来解决业务问题?一开始,作为数据科学家,我建议避开机器学习,这一举动可能会让人觉得奇怪。因为“巨大的力量带来的是巨大的责任”。我们只要确保机器学习模型被建立、部署和仔细监控,以确保它满足并继续满足业务需求。同时,在这个阶段也应该与利益相关者讨论时间表和资源。
数据准备
一旦决定走机器学习的路线,就开始考虑“数据”。这个阶段包括数据收集、数据清洗、数据转换、特征工程和标签(对于监督学习)。这里需要记住的格言是“垃圾输入,垃圾输出”。这个步骤通常是过程中最痛苦的步骤,对于确保模型成功至关重要。确保多次验证数据和特征,以确保它们与业务问题相符。记录你在创建数据集时做出的所有假设。例如:一个特征的异常值真的是异常值吗?
模型构建和分析
在这个阶段,需要构建和评估多个模型,选择最能解决问题的模型架构。选择的优化指标应反映业务需求。现在,有许多机器学习库可以加快这个步骤。记住记录和跟踪你的实验,以确保机器学习流水线的可重复性。
模型服务和监控
一旦我们从前一阶段构建出模型对象,需要考虑如何让最终用户“使用”它。最小化响应延迟,以及最大化吞吐量。部署服务模型为REST API端点,并将其部署到云上的Docker容器或在边缘设备上。即便是顺利部署了服务,但也不能高兴得太早,因为还存在变数。例如,生产中的数据可能会漂移,导致模型衰退,或者模型会受到对抗性攻击。我们需要为机器学习应用建立强大的监控基础设施。这里需要监控两件事:
1.部署环境的健康状况(例如:负载,使用情况,延迟)
2. 模型本身的健康状况(例如:性能指标,输出分布)。
在这个阶段也需要确定监控频率。每天、每周还是每月监控ML应用程序?至此,已经建立、部署和监控了一个健壮的机器学习应用程序。但是,轮子并没有停止旋转,因为上述步骤需要不断迭代。
为了将上述五个阶段付诸实践,我们会举一个案例作为最佳实践的参考。假设你是一家金融科技公司的数据科学家,负责部署一个用于检测欺诈交易的欺诈模型。在这种情况下,首先要深入研究检测的欺诈类型(是第一方还是第三方?)。交易如何被确定为欺诈或非欺诈?是由最终用户报告的,还是你必须使用启发式方法来识别欺诈?谁会使用模型?它将实时使用还是批量模式?回答上述问题对解决这个业务问题至关重要。
接下来,考虑什么解决方案最能解决这个问题。你需要机器学习来解决这个问题,还是可以从简单的启发式方法开始来处理欺诈?所有的欺诈是否都来自一小部分IP地址?
如果你决定构建一个机器学习模型(假设这个案例是监督学习),你将需要标签和特征。你将如何处理缺失的变量?异常值呢?欺诈标签的观察窗口是多少?即用户报告欺诈交易需要多长时间?是否有一个数据仓库可以用来构建特征?在向前移动之前,确保验证数据和特征。这也是与利益相关者就项目方向进行交流的好时机。
一旦你有了所需的数据,就构建模型并进行必要的分析。确保模型指标与业务使用相符。(例如:对于这个用例,可能是第一分位数的召回率)。所选的模型算法是否满足延迟要求?
最后,与工程协调部署和服务模型。因为欺诈检测是一个非常动态的环境,欺诈者努力保持在系统前面,所以监控非常重要。对数据和模型都有一个监控计划。例如,人口稳定性指数(PSI)是常用的跟踪数据漂移的措施。你将多久重新训练一次模型?
现在,你可以成功地通过使用机器学习(如果需要的话!)来减少欺诈交易,从而创造商业价值。
结论
希望在阅读这篇文章后,你能够理解MLOps给企业实现机器学习到部署带来的益处。总的来说,MLOps能够给数据科学团队带来如下优势:
- 解决正确的业务问题
- 使用正确的工具来解决问题
- 利用代表问题的数据集
- 构建最优的机器学习模型
- 最后部署和监控模型以确保持续的成功
然而,要注意常见的陷阱,以确保你的数据科学项目不会成为数据科学墓地的一块墓碑!数据科学应用是一个活生生的东西。数据和模型需要持续被监控。从一开始就应该考虑AI治理,而不是作为事后的想法。牢记这些原则,我相信你可以真正地利用机器学习(如果需要的话!)创造商业价值。
译者介绍
崔皓,51CTO社区编辑,资深架构师,拥有18年的软件开发和架构经验,10年分布式架构经验。
原文标题:How to MLOps like a Boss: A Guide to Machine Learning without Tears,作者:Natesh Babu Arunachalam

