2023年人工智能领域如果只能筛选一个关键词的话,恐怕非“大模型”莫属。大模型的发展在过去一年中,让各行各业发生了天翻地覆的变化,有企业因大模型而新生,有企业因大模型而消亡。企业的变迁跟技术迭代息息相关,而大模型就是新一代人工智能技术下的产物,大模型已经深入各行各业对具体业务进行了全方位的干预,可以说未来没有一个行业能脱离AI大模型的影子。新年伊始之际,人工智能的的发展也将进入下一阶段,对社会生产的改变也将更加明显,下面是根据过去一年人工智能的发展现状对未来一年人工智能发展的预测。
一、以MoE为主的方法将成为大模型研究的新方向
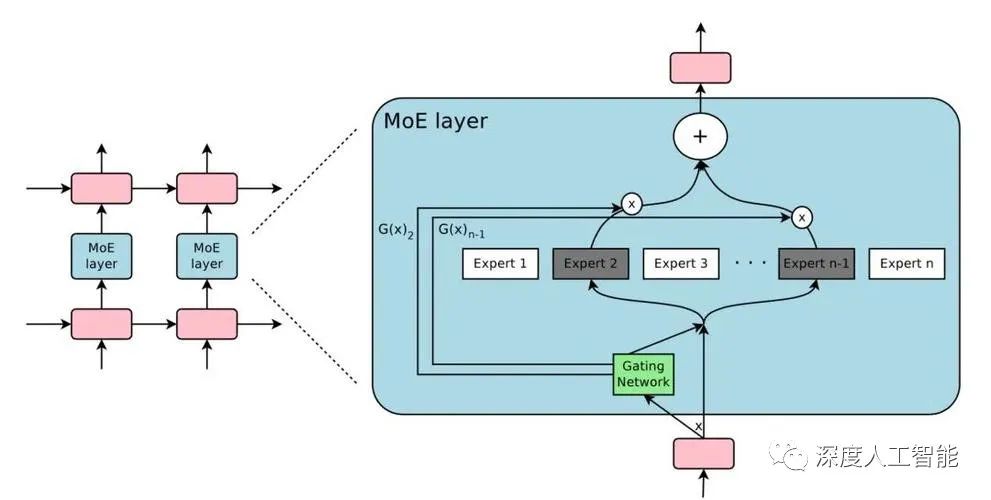
MoE,即Mixture-Of-Experts,是一种深度学习技术,它通过门控网络实现任务/训练数据在不同专家模型间的分配,让每个模型专注处理其最擅长的任务,进而实现模型的稀疏性。这种方法可以在保证运算速度的情况下,将模型的容量提升>1000倍。
MoE模型由两个关键组成部分构成:门控网络和专家网络。门控网络负责根据输入数据的特征,动态地决定哪个专家模型应该被激活以生成最佳预测。专家网络是一组独立的模型,每个模型都负责处理某个特定的子任务。通过门控网络,输入数据将被分配给最适合的专家模型进行处理,并根据不同模型的输出进行加权融合,得到最终的预测结果。
MoE模型已经在一些实际应用中取得了显著的效果。例如,Moët & Chandon,这是一家法国的精品酒庄,也是奢侈品公司LVMH Moët Hennessy Louis Vuitton SE的一部分。他们使用MoE模型来提升其产品的质量和准确性。
在2023年12月份,Mistral AI发布了类GPT-4架构的开源版本Mistral 8x7B模型,这8个70亿参数的小模型组合起来,直接在多个跑分上超过了多达700亿参数的Llama 2。英伟达高级研究科学家Jim Fan推测,Mistral可能已经在开发34Bx8E,甚至100B+x8E的模型了。而它们的性能,或许已经达到了GPT-3.5/3.7的水平。

二、Transformer架构的统治地位将受到挑战
在过去的几年中自从Transformer出现之后,它的架构几乎就是为大模型而量身制作的,简单的前馈神经网络模型能够提供给模型足够大的参数,再加上带有残差和注意力模块编解码结构的堆叠,不仅是参数量更进一步的增大,巍模型提供更强大表示能力,稠密的多头自注意力机制还为模型提供了数据内部不可或缺的关系表达能力。
但是随着底层基础模型技术的研究和发展,逐渐有一些新的模型架构对传统Transformer造成了一定的挑战,当然这种挑战不仅仅局限于学术层面,更多的可能还会在后续的工业界得到证实。
由于Transformer本身参数的增加随着token的增加成2次方的增长,这导致计算成本也在迅速的增长,其次Transformer在参数达到一定量级后也出现了表达瓶颈的现象,由此出现了一些在未来可能会替代Transformer的研究方案。
lRetNet:RetNet(Retentive Network)被设计为大型语言模型的基础架构,RetNet的主要优势在于它能够同时实现训练并行化、低成本推理和良好的性能。RetNet提出了一种名为"retention"的机制来替代传统的"attention"机制。这种机制支持三种计算范式,即并行、循环和分块循环。具体来说,其并行表示允许训练并行化,循环表示使得推理成本低,而分块循环表示有助于有效地进行长序列建模。
lRWKV:RWKV(Receptance Weighted Key Value)将 Transformer 的高效可并行训练与 RNN 的高效推理相结合。RWKV的设计精良,能够缓解 Transformer 所带来的内存瓶颈和二次方扩展问题,实现更有效的线性扩展,同时保留了使 Transformer 在这个领域占主导的一些性质;
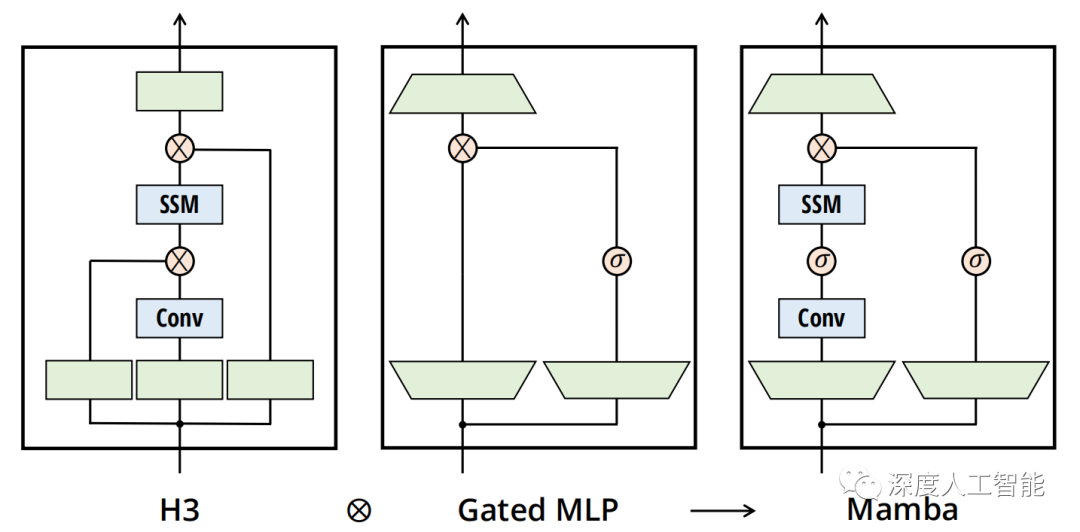
lMamba:Mamba 基于选择性状态空间模型(SSM),Mamba 将这些选择性 SSM 集成到一个简化的端到端神经网络架构中,无需注意力机制,甚至不需要 MLP 块。Mamba 通过让 SSM 参数作为输入的函数,解决了其离散模态的弱点,允许模型根据当前标记选择性地沿序列长度维度传播或忘记信息。Mamba 具有快速的推理(吞吐量比 Transformer 高 5 倍)和序列长度线性缩放。在语言建模任务中,Mamba-3B 模型在预训练和下游评估中均优于相同规模的 Transformer,并且与其两倍大小的Transformer 模型相媲美。

lUniRepLKNet:UniRepLKNet是由腾讯和香港中文大学联合发布的一种基于大核卷积神经网络(CNN)的大模型基础架构。UniRepLKNet采用大核CNN,可以处理多种模态的数据,如图像、音频、时序预测等。UniRepLKNet提出了四条用于大核CNN架构设计的指导原则,并设计了一种硬件感知的并行算法,实现了实际测速优势,在多种模态上均实现了最先进的性能。UniRepLKNet在时序预测的超大数据上用这一为图像设计的backbone达到了最先进的性能。这些特性使得UniRepLKNet成为了一种强大的模型架构,它有效地利用了大核CNN的优点;
lStripedHyena:StripedHyena是由Together AI发布的一种新型人工智能模型,它将注意力和门控卷积结合成了所谓的Hyena运算符。StripedHyena采用了一种独特的混合结构,将门控卷积和注意力结合成了Hyena运算符。这种结构使得StripedHyena在训练、微调和生成长序列过程中具有更高的处理效率,更快的速度和更高的内存效率。在短序列任务中,包括OpenLLM排行榜任务,StripedHyena在性能上超越了Llama-27B、Yi7B以及最强大的Transformer替代品,如RWKV14B。StripedHyena能够处理长序列,这使得它在处理长提示的各种基准测试中表现出色。StripedHyena的设计优化了计算效率,使得它在训练期间能够进行体系结构修改。
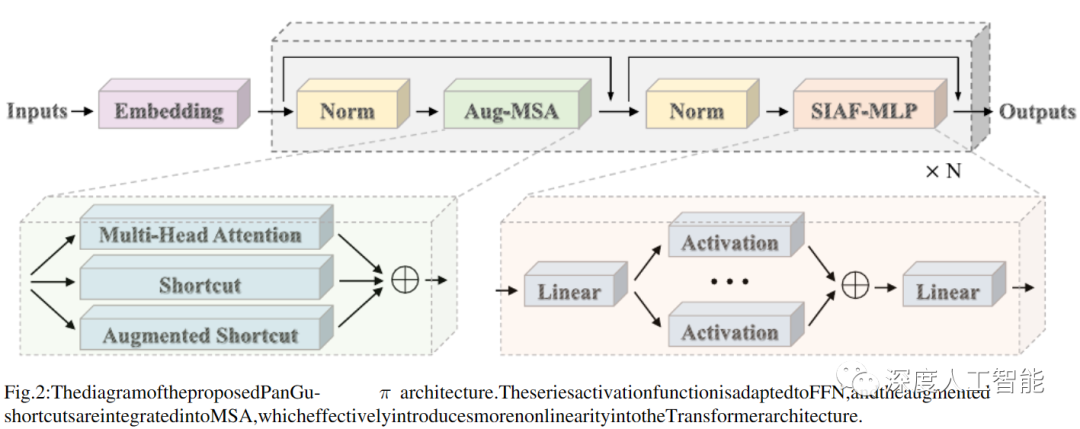
lPanGu-Π:PanguΠ是一种新型的Transformer模型,它针对Transformer的特征坍塌问题和非线性关系进行了优化。在 Transformer 更深层中,特征的秩显著降低,导致所有 token 之间的相似性增加,这极大地降低了 LLM 的生成质量和多样性。非线性对 Transformer 模型的能力有重大影响。增强非线性可以有效地缓解特征坍塌的问题,并提高 Transformer 模型的表达能力。PanGuΠ在前馈网络(FFN)中采用了级数激活函数,并且在多头自注意力(MSA)中集成了增强型快捷连接,这有效地为Transformer 架构引入了更多的非线性。并增广 Shortcut(Augmented Shortcut)来缓解特征坍塌的问题,提高大语言模型的表达能力。

以上这些基础模型框架或者相关微调技术都将会对Transformer的统治地位造成一定的影响,能否完全替代Transformer在大模型一统天下的局面,不仅要看学术界的成果,更要看工业界的行动。
三、大模型免微调方法得到一定的发展
大模型表现能力如此显眼,其中少不了对模型的微调,而近期的一些研究表明通过对alignment tuning的深入研究揭示了其“表面性质”,即通过监督微调和强化学习调整LLMs的方式可能仅仅影响了模型的语言风格,而对模型解码性能的影响相对较小。具体来说,通过分析基础LLMs和alignment-tuned版本在token分布上的差异,作者发现在大多数情况下,它们在解码上表现几乎相同,主要的变化发生在文体方面,如话语标记和安全声明。
研究者提出了一种名为URIAL(Untuned LLMs with Restyled In-context ALignment)的简单、无需调优的对齐方法。URIAL方法利用上下文学习(ICL),通过采用少量精心策划的风格示例和精心设计的系统提示,实现了对基础LLMs的有效对齐,而无需调整其权重。在这个方法中,通过巧妙构建上下文示例,首先肯定用户查询并引入背景信息,然后详细列举项目或步骤,最终以引人入胜的摘要结束,其中包括安全相关的免责声明。
研究发现这样一个直接的基准方法能够显著减小基础LLMs和经过对齐的LLMs之间的性能差距。这表明,通过精心设计的上下文示例,可以在不进行调优的情况下实现对基础LLMs的有效对齐,为对齐研究提供了新的思路。
事实证明,只要基础模型设计的够好,加以优质的数据和足够的训练,完全可以省去微调的步骤,这不但提高了大模型训练的效率,也大大减低的大模型微调的成本。

四、多模态大模型将持续渗透各行各业
随着最近一年来以ChatGPT为主的大模型逐渐走向应用市场,从最初的语言模型应用,已经发展到了视觉模型应用、语音模型应用等多个应用领域,由此也诞生了多模态大模型。多模态大模型,即能够处理多种类型输入(如文本、图像、语音等)的人工智能模型。多模态大模型正在逐渐改变各行各业。
多模态大模型已经在自动驾驶领域得到应用,例如,可以利用多种不同的传感器,例如摄像头、激光雷达、超声波等,来构建一个更加全面和准确的自动驾驶系统。中国科学院自动化研究所的“全媒体多模态大模型”结合新华社全媒体的海量数据积累和媒体融合业务场景,推动了人工智能在视频配音、语音播报、标题摘要、海报创作等多元媒体业务场景的应用。
微软的研究员撰写的综述预测,多模态基础模型将从专用走向通用,未来将有更多的研究关注如何利用大模型处理多模态任务。中国科学院预测,“多模态大模型+小模型”的模式可能成为主流,多模态人工智能产业正在走向场景应用的新阶段。多模态大模型将在未来的人工智能发展中起到重要作用。
这些证据和预测表明,多模态大模型将持续渗透并改变各行各业,为我们的生活带来更多可能性。在新的一年,多模型模型的发展应用将持续深入各行各业,对具体的业务产生不可忽视的影响。

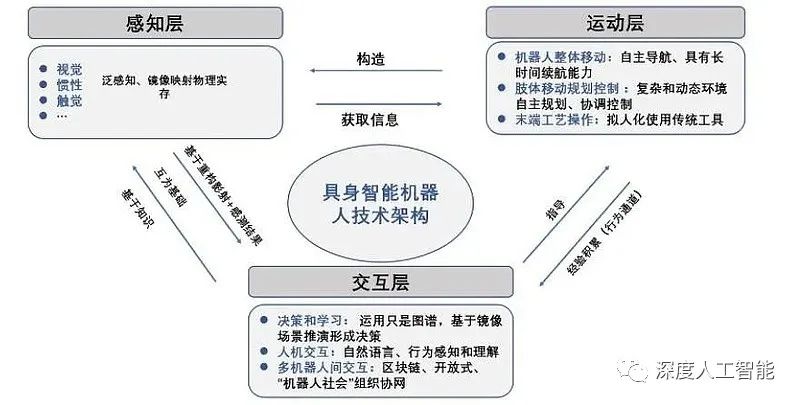
五、具身人工智能开始迅速发展
具身人工智能,也被称为Embodied AI,是指具有物理实体并能与真实世界进行多模态交互的智能体。具身智能(Embodied Intelligence)是一种智能系统的设计理念,其目标是通过将感知、决策和行动融合在一起,使机器能够像人类一样具备身体和运动能力。具身智能的核心理念是利用机器的身体结构和动作能力来增强其智能表现和解决复杂任务的能力。传统的人工智能系统主要关注于数据处理和算法的优化,而具身智能则更加注重机器与环境的互动和交流。
1986年,著名的人工智能专家布鲁克斯 (Rodney Brooks)提出了具身智能的理论,他认为智能是具身化和情境化的,传统以表征为核心的经典AI进路是错误的。
李飞飞教授提出了一套新的计算框架——DERL(deep evolution reinforcement learning)深度进化强化学习,这篇文章提到了生物进化论与智能体进化的关系,并借鉴了进化论的理论应用于假设的智能体(unimal宇宙动物)的进化学习中。
目前,具身智能已经成为国际学术前沿研究方向,包括美国国家科学基金会在内的机构都在推动具身智能的发展。谷歌公司的Everyday Robot已经能够将机器人和对话模型结合到一起,形成一个更大的闭环。UC伯克利的LM Nav用三个大模型(视觉导航模型ViNG、大型语言模型GPT-3、视觉语言模型CLIP)教会了机器人在不看地图的情况下按照语言指令到达目的地。
基于形态的具身智能研究,例如机器人关节控制,使机器人完全依靠自身形态即可实现对整体行为的控制。具身人工智能正在快速发展,并在人工智能领域中占据越来越重要的地位。

六、通用人工智将进入爆发的前夜奇点
通用人工智能(Artificial General Intelligence,AGI)是指一种具备与人类相似或超越人类智能水平的人工智能形式。与狭窄人工智能(Narrow AI)不同,狭窄人工智能是专注于执行特定任务或解决特定问题的人工智能形式。通用人工智能则是更全面、灵活,能够处理多个不同领域的任务,具有类似人类的学习能力和智能适应性。随着生成式人工智能的发展,未来的人工智能技术发展已经到了通用人工智能前夜的爆发奇点。
麦肯锡的最新年度全球调研结果证实,生成式人工智能(简称GenAI)工具已出现爆炸式增长。许多此类工具至今推出尚不满一年,但已有1/3的受访者表示,其所在组织会在至少一项业务职能中经常使用GenAI。
OpenAI发布了「AGI 路线图」,详细解释了这家前沿研究机构对通用人工智能研究的态度。OpenAI不断构建出更为强大的AI系统,希望快速部署AGI,以积累在相应的应用经验;OpenAI正在努力创建更加一致和可控的模型;OpenAI希望全球范围内解决三个关键问题:人工智能系统的治理问题,AI系统产生的收益的分配问题,以及访问权限的共享问题。OpenAI预计给世界带来巨大变化的AGI在最后阶段一定会出现。
国内科大讯飞副总裁、研究院院长刘聪提出,未来通用人工智能发展将呈现三个趋势:一是向多模态、多语言的方向发展;二是更加可信和可解释,解决幻觉问题和安全问题;三是必须站在软硬件全自主创新的基础上发展大模型技术和产业。
麦肯锡预测,通用人工智能的潜在经济价值在17万亿至26万亿美元之间,并且追求这种价值的公司比例也在持续增加。
这些证据和预测表明,未来一年可能是通用人工智能前夜的爆发奇点,我们有理由期待通用人工智能的快速发展和广泛应用。
七、垂直领域大模型的发展将进入平稳期
垂直领域大模型是针对特定领域或任务进行深度学习训练的超大规模模型。相较于通用大模型,垂直大模型具有更强的领域专业性和任务针对性,能够更好地解决特定领域的问题和提供更加精准的服务。
随着各行业中垂直类大模型应用的持续爆发,大模型对各行业的影响已经进入了顶峰时刻,如医疗、教育、交通、法律、媒体等很多能够被大模型最容易改变的行业都已经与大模型深度结合,相关的企业也都在紧锣密鼓的部署大模型的产业链。从时间节点上来说,在未来一年中,垂直类大模型的应用已经过了爆发期,将会进入平稳的发展期,持续释放行业需求和红利。
垂直大模型正加快覆盖各行各业。例如,携程集团发布了国内首个旅游行业垂直大模型“携程问道”;华为发布了金融、电力、药物分子三个垂直领域大模型;京东表示发布的千亿级大模型,进一步聚焦行业应用。
未来垂直领域大模型的研发将会持续投入加大,国内多家企业加大“垂直大模型”研发投入,并在旅游、商业、金融、医疗、办公协同等领域加快应用。
业内人士认为,目前,国内出现了做通用大模型和做垂直大模型两条路径。算力、大规模数据、高成本人才成为大部分企业入局通用大模型的“拦路虎”。深度定制、广阔的场景应用,则催生了国内垂直领域大模型的开发。
腾讯发布的大模型时代AI趋势报告显示,未来的数字化商业将分为大模型基础设施型企业、垂直行业领域的小模型应用企业,以及更加贴合个人用户的模型应用和服务。这一生态的建立和发展,将更广泛地赋能各行业应用,加快社会各领域数字化转型、智能化发展,带来全社会的生产效率提升。垂直领域大模型的发展已经进入平稳期,其应用和影响将会越来越广泛。

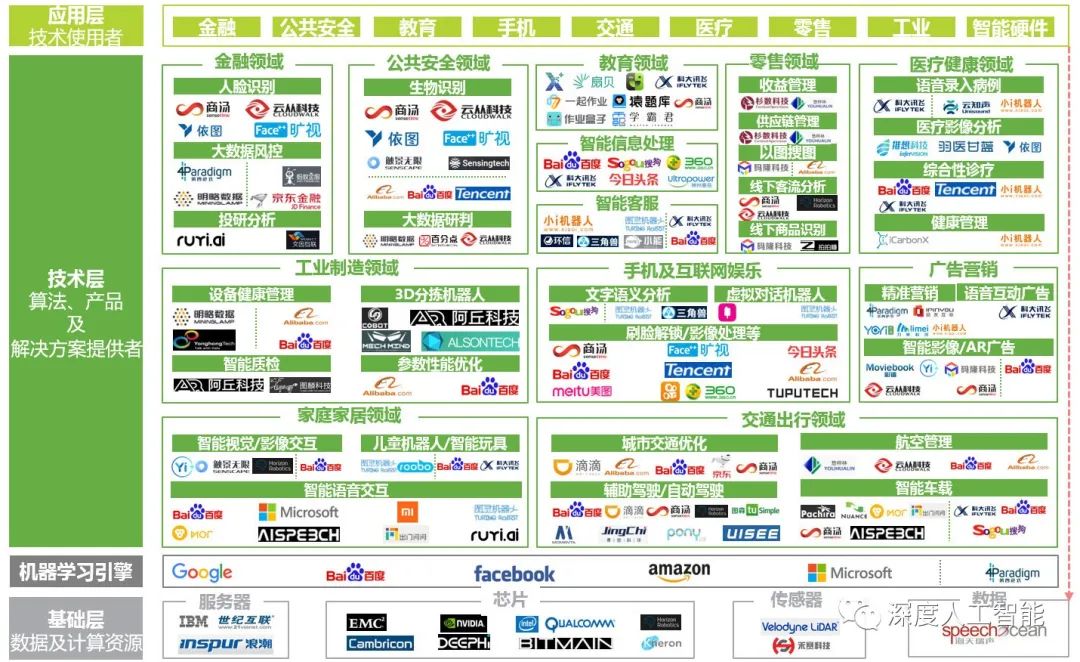
八、国内人工智能技术突破瓶颈开始快速发展
人工智能的发展源于上个世纪50年代在美国达特茅斯会议上的共识,距今已经有70多年了,也就是说人工智能其实不是一门新的学科和技术,这几十年来,全球研究人工智能的技术人员主要都集中在美国、加拿大、英国等国家,相关的技术成果也都出自于上述国家的技术团队。而我国在过去几十年间,真正研究人工智能技术的团体和个人则要少得多,这主要是因为人工智能在过去几十年间都是以基础研究为主,很少出现应用型的人工智能产品。
国内真正大规模开始研究人工智能技术的时间节点在2016年前后,2016年3月,DeepMind团队研发的AlphaGO与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜。此后人工智能技术的热度不断地被刷新。
但是这些热点事件都是在国外,国内几乎没有报出过有关人工智能技术发展的轰动性事件,更多的是追随国外技术的脚步发展,这也很正常,主要是国内无论从技术人员储备,还是从技术沉淀上来说都比不上国外。
不过随着近几年的追赶,国内技术团队在一些领域也逐渐绽放光芒,技术成果也可圈可点,从技术上来说,有了一定的突围,产业规模也连年攀升。最新公布的统计数据显示,中国人工智能核心产业规模达到5000亿元,企业数量超过4400家,已建设近万个数字化车间和智能工厂。
另外,近几年国内人工智能的论文数量激增,泥沙俱下,导致部分论文质量不高,但这并不能说明人工智能发展停滞不前,而是表明目前有更多的研究人员投入到了这个火热的研究方向。在2023年,人工智能技术领域出现了一些重要的突破,这些突破已经开始或有潜力改变多个行业和领域。
在未来一年内,国内的人工智能技术将突破瓶颈开始快速发展。这将为中国的科技创新和经济发展提供强大的动力。

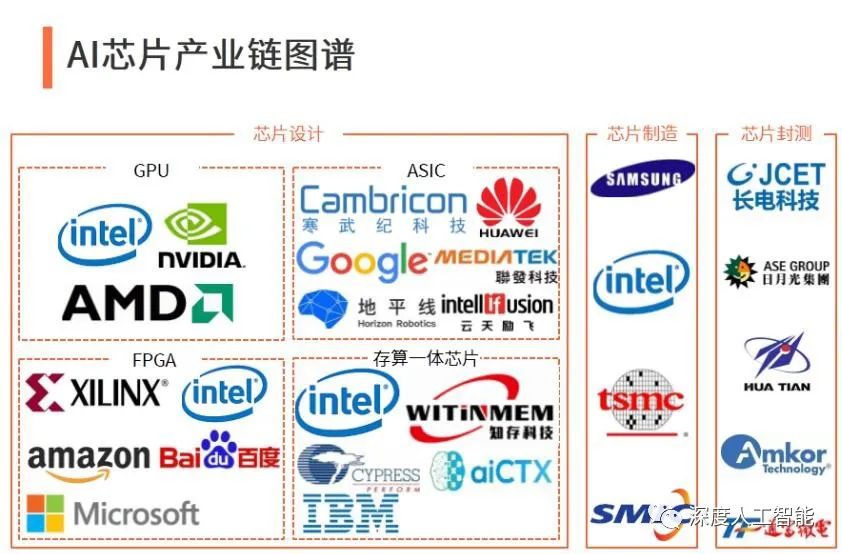
九、英伟达在人工智能芯片领域依然遥遥领先
2023年,我国智能芯片、开发框架、通用大模型等创新成果不断涌现:华为、寒武纪、景嘉微、壁仞科技、摩尔线程、燧原科技等芯片公司推出了不同设计架构、不同应用场景的AI推理和训练任务的芯片加速卡。
而美国在人工智能芯片、算法、机器学习等核心技术的原创方面,至今仍大幅领先。英伟达的GPU和谷歌的TPU在芯片领域具有行业领先地位。美国的AI产业整体也领先与世界各国,技术布局更广、更精。国内除了百度的飞桨外,其他主流深度学习开源框架均来自于美国。
英伟达是全球GPU龙头企业,其产品线涵盖了A100、H100、L40、L40S、GH200等产品。英伟达的数据中心解决方案整体提供了NVIDIA加速计算统一平台,从AI、数据分析,到高性能计算 (HPC),再到渲染,数据中心都是攻克某些重要挑战的关键。
根据Informa PLC旗下的英国研究咨询公司Omdia的调查显示,现阶段英伟达占大型数据中心AI专用计算市场总收入的80%左右。英伟达2024财年呈现快速增长态势。FY24Q2营收135亿美元,同比增长101%,环比增长88%;FY24Q3收入181亿美元,同比增长206%。
英伟达与联发科合作的首款芯片将用于智能座舱,预计2025年问世,并在2026年至2027年投入量产。英伟达推出了首款面向AI基础设施和高性能计算的数据中心专属CPU——NVIDIA Grace,由两个CPU芯片通过最新一代NVLink-C2C技术互联组成。
这些证据表明,英伟达在人工智能芯片方面的技术优势、市场份额、发展势头、合作伙伴和创新能力,将使其在未来几年内依然领先全球。
不过中国在计算机视觉、语音识别等领域已与美国对齐。例如,百度预训练模型ERNIE超越微软、谷歌拿下Glue冠军,商汤一举拿下Image Net 2016年三项冠军;云从科技在Librispeech上刷新世界纪录。此外中国在人工智能芯片的专利总量最多且增速最快,国内机构在AI芯片领域的专利布局力度提升明显。

十、决策式人工智能将成为下一个风口
决策式人工智能,也称为决策智能,是一种依托多种软件技术的决策优化实用技术,通过最大化发挥和利用数据分析、机器学习和人工智能的潜能,帮助人类以更少的成本完成更多、更高效的决策。自生成式人工智能爆发之后,决策式人工智能将会成为下一个值得关注的风口。
未来,决策AI将朝着三大方向发展。第一,智能体的数量越来越多,从 1v1 的围棋到 MOBA、足球等更大规模的多智能体场景。第二,人机交互方式更多元,从竞技对抗向博弈、协作演进。第三,决策环境日益复杂,从最早的 2D 场景到 2.5D 游戏,再到更接近真实场景的 3D 开放世界。
Gartner预测,到2024年30%的企业机构将使用新的“社会之声”指标,来解决其面临的社会问题,以及评估数字道德对其业务绩效的影响。此外,截至2020年,决策类人工智能市场规模达268亿元,近4年年均复合增长率实现83.5%,预计2020-2025年将保持47.1%的年均复合增长率,并在2025年突破1847亿元。
决策智能不仅能提升运营质量和决策水平,更可以创造更多业务价值,还能够产生新的业务模式和利用数据直接变现。
这些证据表明,决策式人工智能将成为下一个风口,其发展前景广阔,应用价值巨大。值得注意的是,决策式人工智能不仅是辅助人类做决策,在更多的领域可以完全替代人类做决策。可以想象,无论是实现具身人工智能,还是实现通用人工智能,都离不开决策式人工智能的帮助。


2023年是AIGC元年,也是AI大模型元年,在这一年人工智能的落地应用出现了井喷式的增长,不但降低了生产成本,提高了生产效率,也为各行各位带来了众多的机会。2024年人工智能的发展将会上升一个新的台阶,为人类的文明发展提供更多的帮助!

