
前言:前端领域的自动化测试
一直以来对于前端同学来说,自动化测试都是一个比较特殊的命题。一方面,大家其实都知道自动化测试的好处,做了什么改动只要跑一遍测试用例就知道有没有改挂了之前的逻辑,进行修改时也更有底气。而另一方面,前端本身就具有特殊性,活动页从需求评审到正式上线可能在一周内就完成了,这种迭代速度还写测试用例就是折磨自己。
但实际上,自动化测试在前端工程中也是相当重要的一部分。即使是快速迭代的活动页面,也会有通用的工具函数与 SDK,对这一部分的代码进行测试用例的完善是有必要且意义重大的,而对于某些流量巨大且长期存在的页面,我们甚至需要进行多种测试场景的保障。
然而由于这两种情况的存在,很多前端同学其实都对自动化测试的认知相当空白,它有哪些分类?有哪些推荐的实践?有哪些框架与方案?而这篇文章的目的就是进行一个基础的扫盲,至少完成阅读以后你会知道如何为项目编写测试用例,以及应该编写哪些场景的测试用例。
单元测试与集成测试
单元测试(Unit Testing)正如其名,其中的测试用例应当是针对代码中的各个单元的,如前端代码中,每一个工具方法都可以被作为一个单元,对应一个独立的测试用例。但这么说并不意味着你要写出非常细粒度的代码——这不是没事折磨自己吗?我通常使用“功能单元”的方式来确定粒度,比如生产薯条的流水线上,清洗-削皮-切片-包装就是四个完全独立的功能单元。
你可能会感到疑惑,这四个功能单元明明存在依赖关系,为何说是完全独立的?这是因为在单元测试时,非常重要的一个步骤就是对当前测试单元的外部依赖进行模拟,比如我在测试削皮功能时,会直接给到“已经清洗完毕的土豆”,然后检查“削皮后的土豆”,而不会真的去调用前后的功能单元。
- 常见的模拟操作可以分为 Fake、Stub、Mock、Spy 这么几种,我们在下文会有更详细的介绍。
一种常见的情况是工具方法中会基于外部依赖的表现执行不同分支的代码(if/else,try/catch,resolve/reject 等)。这种时候,我们需要做的就是通过修改外部依赖的表现,来检查工具方法内部各个代码分支的执行情况。比如,在 fetch 成功返回时应当调用 processData 方法,在 fetch 失败时应当调用 reportError 方法,此时你就可以篡改掉 fetch 的实现,然后检查 processData 、reportError 方法是否被调用(注意,这两个方法也需要被模拟(Stub / Spy) ,然后才能检查它们的调用情况)。
当然,完全模拟所有外部依赖是最理想的情况,在很多时候一个工具方法可能具有许多外部依赖,此时你可以省略掉其中能确定无副作用(如 logger 这样的纯函数),或者是与核心逻辑无关的部分。
我们知道,测试用例也可以反过来对代码产生检查作用,而在单元测试阶段这种作用基本是最明显的,比如你可以很容易发现某一处功能单元设计得过于耦合,或是某一外部依赖将导致代码进入错误分支等情况。
目前推荐的单元测试方案主要有这么几种,Jest、Mocha、Sinon、Jasime 以及 AVA,它们之间各有优劣,这里不做比较。但需要注意的是,一套完整的,能够满足实际需求的单元测试方案,通常意味着需要包括这么几个功能:
- 断言,Jest 提供了注入到全局的 expect 风格断言(expect(1+1).toBe(2)),而 Sinon 提供的则是类似 NodeJs asserts 模块风格的断言(``sinon.assert.pass(1 + 1 === 2)`),而 Mocha 则不绑定断言库,你可以使用 asserts 模块或者 Chai 来进行断言。另外,断言又包括了几种不同的风格,我们同样在下文讲解。
- 用例收集,编写测试用例时我们同样需要基于功能单元区分,常见的方式就是 describe 收集一个功能单元,内部又使用 it / test 来进行功能单元各个逻辑分支的验证。如:
describe('Utils.Reporter', () => {
it('should report error when xxx', () => {})
it('should show warnings when xxx', () => {})
})
- 模拟功能(Stub 、Fake Timers 等),包括对一个对象的 Spy,一个函数的 Stub,对一个模块的 Mock,都属于模拟的范畴。
- 测试覆盖率报告,这一功能常见的方式是通过 istanbul (1.0版本,2.0 更名为 nyc)或 c8 来进行实现,其原理包括代码插桩与使用 V8 引擎内置功能两种,这里不再赘述。另外一个常见的场景是输出其他语言格式的覆盖率报告(如 JUnit),社区也通过 Reporters 的机制为这些测试框架做了支持。
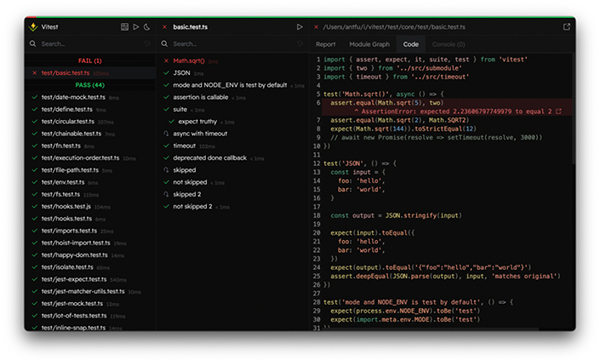
如果你此前并没有对这些单元测试方案非常熟悉,那我推荐你了解一下 Vitest ,来自 antfu 的作品,特色是快(毕竟基于 Vite)以及对 TypeScript、ES Module 的良好支持,我目前在工作中的单元测试也已经全部迁移到 Vitest,同时 Vitest 还自带了 UI 界面,让你可以更享受编写测试并看着它们一个个通过的过程。
如果说单元测试是为了测试单个功能单元,那么集成测试(Integration Testing)很明显就是为了测试多个功能单元的协作。但需要注意的是,多个功能单元协作并不意味着对整个系统(流水线)进行完整的功能测试,通常我们还会将几个功能单元分散开进行组合,成为系统的某一部分,比如清洗-削皮作为预处理功能,需要确定一箩筐土豆能否正确地变成干净的去皮土豆,切片-包装作为核心功能,需要确定去皮土豆能变成冷冻薯条。
而要进行集成测试的编写,其实我们仍然只需要使用单元测试方案即可,因为本质上集成测试就是同时对多个功能单元进行测试,我们验证的范畴也随之扩大了而已。
而关于集成测试的维度拆分则并没有准确的界限,你可以像上面那样将预处理功能作为一个系统部分,也可以将整个流水线作为一个系统部分(还有供应链部分、烹饪部分与服务部分),按照你的实际业务场景就行。
Mock、Fake、Stub
很多时候测试用例的运行时是受限的,比如我们并不希望真的发起网络请求,或者是和数据库交互,以及 DOM API 的操作等。这个时候我们会使用一系列模拟手段,来特定地模拟一个可交互的对象,并通过修改它的行为来检查预期的处理逻辑是否执行。
这个模拟行为通常被直接称为 Mock,但实际上,由于模拟的对象类型以及注入的模拟逻辑,更准确的描述是将这些行为划分为三大类。首先是最常用的 Stub ,假设我们在为 UserService 编写单元测试,其内部注入的 PrismaService 负责数据库的读写,我们可以使用一个 PrismaServiceStub 替换掉实际的服务,并且在其内部提供对应 PrismaService.user.findUnique 这样的方法,然后在我们调用 UserService.queryUser 时,就可以检查 PrismaServiceStub 上对应的方法是否被预期的入参调用,而其出参是否被预期地处理后返回。Spy 也可以认为是 Stub 的一种,但它更强调“是否按照预期调用”这个过程,我们甚至可以仅仅监听一个对象而无需提供模拟实现(如 console 这样的 API)。
而如果我们不希望替换掉 PrismaService,而是希望它真的去进行数据读写,但不是对真实的数据库,就可以提供一个 Fake 的数据库——比如一个对象,这样对数据库的读写就变成了对内存对象的读写,变得更加快捷和稳定,这就是 Fake。另外一个常见的 Fake 场景就是定时器,常见的单元测试框架都提供了 Fake Timers 的功能支持。
而 Mock 其实和 Stub 也非常类似,但 Mock 更像是其中“预期的入参”,而并不关注返回值,我个人理解通常项目中 fixtures 文件夹下的各种对象和 JSON 就是典型的 Mock 。
当然,Mock、Stub、Spy 三者还是非常相似的,我们也并不是必须搞清楚其中的差异,因为它们的本质都是模拟罢了。
断言:expect、assert、should
我们常见的断言包括 expect 与 assert 形式,NodeJs 提供了原生的 asserts 模块让你来编写一些简单的断言,你可以在实际代码中也使用断言来确保逻辑正确运行,而 expect 形式则通常只见于测试用例中。如检查一个函数的调用和比较两个对象,两种风格分别是这样的:
expect(mockFn).toBeCalledWith("linbudu");
assert.pass(mockFn.calls[0].arg === "linbudu");
expect(obj1).toEqual(obj2);
assert.equal(obj1, obj2);
通常我个人更喜欢命令式风格明显的 expect 断言,而除了这两种风格以外,其实还有一种 should 形式的链式风格断言,它写起来是这样的:
mockFn.should.be.called(); obj1.should.equal(obj2);
值得一提的是在 Chai 这个断言库中对以上三种断言风格都进行了支持,如果你有兴趣,不妨都试一试。
前端页面中的组件测试与 E2E 测试
单元测试和集成测试是前后端应用中通用的概念,而完成了对基础功能单元的测试以后,我们需要更进一步,关注领域中特定的功能,比如从前端视角来看一个组件的 UI 与功能,从后端视角来看一个接口面对千奇百怪入参的响应。
在当今的前端项目中,组件化应该是最明显的一个趋势,那么进行组件维度的测试也自然是相当有必要的。以 React 组件为例,我们可以模拟这个组件的入参,并观察其实际渲染的 UI 组件是否正确,以及使用快照的方式,来检查组件的实际渲染是否一致。
目前使用的组件测试方案通常是和框架绑定的,如 React 下的 @testing-library/react 和 Enzyme,Vue 下的 @vue/test-utils,Svelte 下的 @testing-library/svelte,这是因为本质上我们是在孤立地渲染这个组件,并模拟框架行为来验证其表现。
在组件测试方案中,我更推荐 @testing-library/react (还包括 @testing-library/react-hooks),Enzyme 的 API 要更加复杂,同时其目前应该已经不再维护(或是维护力度堪忧)。使用其编写的测试用例是这样的:
import * as React from 'react'
function HiddenMessage({children}) {
const [showMessage, setShowMessage] = React.useState(false)
return (
<div>
<label htmlFor="toggle">Show Message</label>
<input
id="toggle"
type="checkbox"
onChange={e => setShowMessage(e.target.checked)}
checked={showMessage}
/>
{showMessage ? children : null}
</div>
)
}
export default HiddenMessage
import * as React from 'react'
import {render, fireEvent, screen} from '@testing-library/react'
import HiddenMessage from '../hidden-message'
test('shows the children when the checkbox is checked', () => {
const testMessage = 'Test Message'
// 将组件模拟渲染出来
render(<HiddenMessage>{testMessage}</HiddenMessage>)
// 基于模糊查询来验证 DOM 元素的存在
expect(screen.queryByText(testMessage)).toBeNull()
// 同样基于模糊查询来触发事件
fireEvent.click(screen.getByLabelText(/show/i))
// 验证结果是否符合预期
expect(screen.getByText(testMessage)).toBeInTheDocument()
})
单元测试、集成测试、组件测试,看起来我们已经非常完美地使用自动化测试从不同场景与不同维度进行了功能的验证,但实际上,我们还少了一个非常重要的维度——用户视角。在程序最终交付验收时,我们可爱的测试同学会来把各个功能和链路都检查一遍,而即使你已经写了巨量的测试用例,还是有可能会被发现大量的问题,这就是因为视角不同。作为程序的开发者,你清楚地了解程序的控制流走向,也对每一个分支了然于胸,所以在编写测试用例时你其实更像是上帝视角。
要从用户的视角出发,实际上我们只需要屏蔽对程序内部的所有感知,而只是去使用这个程序即可。这样的测试被称为端到端测试(End-to-End Testing,E2E),它不再关注内部功能单元的细节,而是完全从外部还原一个真实的用户视角,如前端应用中,用户登录-搜索商品-加入购物车-编辑商品-结算商品的一系列交互,谁管你的登录背后隐藏了多少权限分级,商品货架分级设计得多么精细,只要这个流程无法顺利走通,那你的系统就是有问题的。
而既然 E2E 测试是在模拟用户行为,那么其实我们所需要做的就是使用用户的环境来运行系统罢了。如对于前端页面,其实就是浏览器(更准确地说是浏览器内核),而对于后端服务则是客户端。
以 Cypress 的功能为例,来看看我们是如何模拟用户行为的:
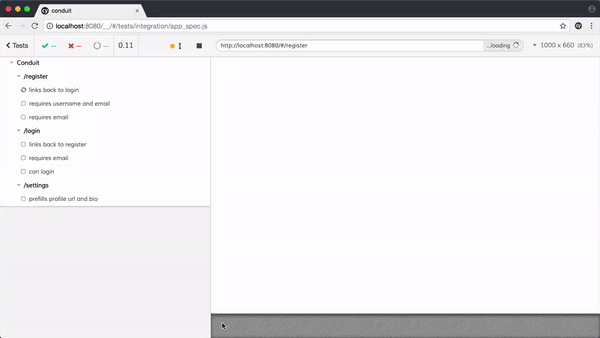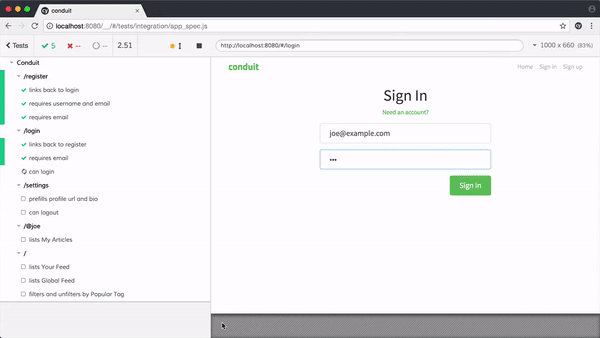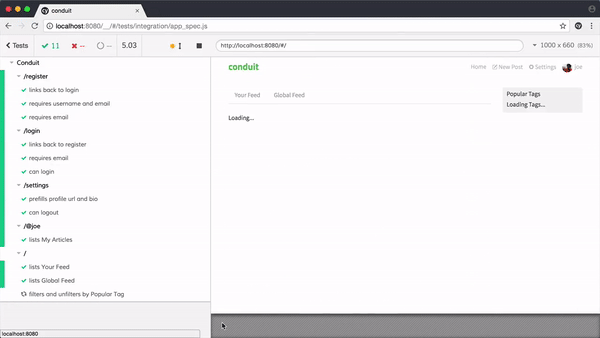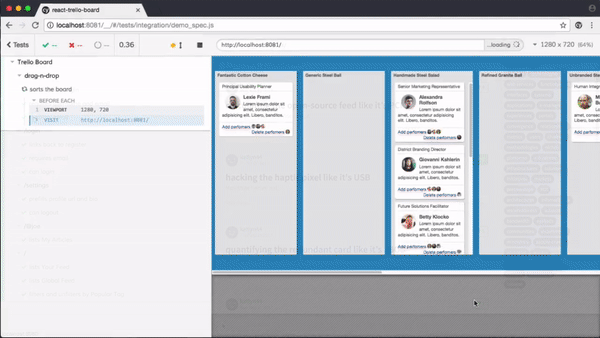
在前端领域中编写 E2E 测试,常见的 E2E 测试框架主要包括 Puppeteer、Cypress、Playwright、Selenium 这么几种。它们之间各有优劣,适用场景也有所不同,我们会在下面进行比较。
与其他测试场景的重要不同之一,就是 E2E 测试是可以由测试同学来编写的(如支持 Python 和 Java 的 Selenium),在产品进行迭代的同时,测试同学会按照功能点变化对应地完善测试用例,同时确保以往所有功能的测试用例不受影响。
Puppeteer、Cypress、Playwright 的取舍
前端 E2E 测试目前常用的包括 Puppeteer、Cypress、Playwright 这么几款,这就可能让你感到选择困难,到底应该选哪个?万一选了一个,写着写着发现不符合需求了,咋办?这一部分我们就来简单介绍一下它们。
先上结论:非常简单的场景使用 Puppeteer(需要搭配 Jest-Puppeteer),PC 应用使用 Cypress,移动端应用使用 Playwright。
接着我们再来一个个解释。首先是 Puppeteer,认真地说,它就不应该用来做 E2E 测试,因为人家真的就只是一个无头浏览器,你要用它来写写爬虫之类的倒还好,强行霸王硬上弓要人家给你干 E2E,一方面是只支持 Chrome + Chromium 内核,另一方面人家不带断言库,你还得带一个 Jest-Puppeteer 一起。但如果是真的非常非常简单的场景,你还是可以用 Puppeteer ,加上 NodeJs 的基础断言库,通过自动化方式确定一些页面功能还是没问题的。
然后是 Cypress ,其场景从人家的 Slogan 其实也能感觉出来:Fast, easy and reliable testing for anything that runs in a browser,注意 in a browser,其实人家就是提供了无头浏览器,断言,GUI,以及 Web 下的各种 API ,然后你就可以完全模拟使用浏览器进行的一切行为了。同时 Cypress 也通过代码插桩的方式支持了覆盖率报告相关的能力。需要注意的是,Cypress 只支持浏览器维度的配置,如 chrome(也支持chromium)、edge、firefox。
因此,如果你更侧重于检查应用在移动端的表现,那其实应该使用 Playwright 。为什么?Playwright 支持同时运行多个 project,这些 project 可以被配置为使用浏览器内核(检验 PC、桌面端场景),也可以被配置为使用内置的 devices 预设,来检验其在移动端的表现,这些预设包括了视口大小、默认浏览器内核(chromium,webkit,safari 等)等等,参考官网的示例配置:
// playwright.config.ts
import { type PlaywrightTestConfig, devices } from '@playwright/test';
const config: PlaywrightTestConfig = {
projects: [
{
name: 'Desktop Chromium',
use: {
browserName: 'chromium',
viewport: { width: 1280, height: 720 },
},
},
{
name: 'Desktop Safari',
use: {
browserName: 'webkit',
viewport: { width: 1280, height: 720 },
}
},
{
name: 'Desktop Firefox',
use: {
browserName: 'firefox',
viewport: { width: 1280, height: 720 },
}
},
{
name: 'Mobile Chrome',
use: devices['Pixel 5'],
},
{
name: 'Mobile Safari',
use: devices['iPhone 12'],
},
],
};
export default config;
在我所在的团队,目前也正在基于 Playwright 建立 E2E 测试用例,来更方便快捷地保障核心应用的页面功能。
最后,如果你并不是在开发一个前端应用,而是在开发一个 UI 组件库,那你可以使用 StoryBook 提供的测试能力(基于 Jest 与 Playwright),这样一来你既能够基于 StoryBook 获得组件的可视化文档说明,也可以获得自动生成的 E2E 测试用例:
后端服务中的 E2E 测试与压力测试
而对于后端服务中的测试,由于我暂时还没有比较深入地实践,这里就只简单介绍下 Node API 中的 E2E 测试、压力测试。
上面我们已经提到,对于后端服务来说其实用户就是各个客户端,而我们也只需要模拟客户端,向 API 发起请求,模拟登录态信息和各种参数,然后查看最终返回的结果是否符合预期即可。在这个过程中,API 由哪个 Controller 承接,调用了哪些 Service,走过了哪些 Middleware ,我们都不应该也无需关心。而假装自己是客户端的方式就简单多了,常见的方式是使用 supertest 。另外,通常后端服务的 E2E 测试也应该是尽量模拟完整的交互过程:上传商品-编辑商品-上架商品-下架商品-...,只不过这个过程并不像在前端那样直观。
另外后端服务中的 E2E 测试如何 Mock 也有不同的情况,如果希望尽可能模拟用户,可以使用专用的测试环境数据库,但这样测试的执行就不完全稳定。如果希望从简,那么可以像单元测试与集成测试中那样模拟掉外部依赖。另外,部分 NodeJs 框架也直接提供了原生的测试支持,如 @nestjs/testing,@midwayjs/mock 等等。
另外一个后端服务特殊的测试场景则是压力测试,在某些时候也可以被等价于性能测试,从某些方面它其实也是在模拟用户,只不过不是模拟一个用户的交互行为,而是模拟较大量级的用户访问,以此来测试服务的性能。本质上压力测试并不是在测试 API 的逻辑,而是承载 API 的服务器性能与负载均衡相关逻辑。进行压力测试可以很简单地使用脚本开多线程并发请求,也可以使用 Apache Bench、Webbench、wrk(wrk2)测试工具,或者 npm 社区也有 autocannon 这样的实现。
在压力测试下,我们主要关注这么几个指标:
- 每秒请求数 RPS,Request Per Second,更常见的称呼是每秒查询数 QPS,Query Per Second,它代表了到达服务器的请求数量。
- 并发用户数 CL,Concurrency Level,不同于 RPS,并发数代表了当前仍未完结的等待处理的请求。举例来说,假设某个神奇 API 的请求处理速度非常快,每个请求的处理时间无限趋近于 0 ,那么即使其 RPS 可能达到一百万,并发数却也非常低(趋近于0)——因为它处理的实在是太快了,几乎不需要同时处理两个请求。
- 每秒事务数 TPS,Transactions Per Second,TPS 有点类似于 QPS,但它所关注的事务其实是比请求-响应过程更具象的过程,举例来说,访问 server/index.html ,实际上还访问了 server/index.css 与 server/index.js 文件,那么这个过程实际上只会记为一次事务,但会记为三次查询。
- 响应时间 RT,Response Time,一个请求从进入到带走响应的耗时,这个耗时包括了等待时间-处理时间-IO读写时间-响应到达时间。
除了这些指标以外,我们还会关注服务器当前的性能指标,如内存与 CPU 占用率,驻留集(RSS,当前进程获得分配的物理内存,包括堆、栈与执行代码段等),你也可以使用 NodeJs 提供的 --prof --prof-process 等启动参数,或使用 heapdump 提供的内存快照打印功能来帮助分析 Node API 的性能。
尾声
除了以上介绍的这些自动化测试分类,其实还有着前端页面的性能测试(如基于 LightHouse、Performance API),主要关注各种“首次”的指标,如首屏绘制、可交互时间、最大内容绘制等等,基于 axe-core 的可访问性测试(Accessibility Testing),关注网页的可访问性,以及一些相对少见的场景,如基于 Needle 的 CSS 测试、基于 Coffee 的命令行应用测试,以及混沌工程理念中的混沌测试等,这些概念要么在社区里已经存在大量的高质量介绍文章,要么我并没有深入了解过,在这里就不赘述了。
另外,想要进一步地保障页面的功能稳定性,监控平台(白屏,JS Error,404)这一类的存在也是相当有意义的,但这一部分功能已经存在太多方案,社区的 Sentry,以及各大厂内部自己建设的平台等等,这里就不再赘述。
这篇不长也不短的小作文里,我们基本上把前端开发者会接触到的自动化测试种类都了解了一遍,包括它们的使用场景,实践方式,以及可选的库/框架。在完成全文阅读后,如果你恰好在开发“值得投入精力编写测试”的应用,不妨思考下,上面是否恰好有符合你所需求的部分。

