一 、深入理解稳定性与高可用性
稳定性与高可用性是老生常谈的两个词。凭借经验和感受我们知道,提高系统的这两项指标,系统会更加健康,产品也会有更好的用户体验。但是如果要给稳定性和高可用性下一个定义该如何表述?稳定性和高可用性这二者又有何区别和联系?我认为首先要理解好这两个问题,才能够设定清晰的目标,系统地制定完整可行的方案。 在维基百科上搜索稳定性,定义如下:
稳定性是数学或工程上的用语,判别一系统在有界的输入是否也产生有界的输出。若是,称系统为稳定;若否,则称系统为不稳定。
再看看高可用性的:
高可用性(英语:high availability,缩写为 HA),IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。是进行系统设计时的准则之一。高可用性系统与构成该系统的各个组件相比可以更长时间运行。
首先从稳定性的定义中提炼出关键的词语 -- 系统、输入、输出。在蚂蚁当下的技术架构中,可以把一个应用当做系统,应用之间的服务请求为输入,服务响应为输出,当服务响应符合预期时认为应用系统是稳定的。当他们相互组合形成一个更大的系统,作为业务产品对用户表达时,用户的请求作为输入,产品的表达作为输出,当产品功能正常运行时可以认为产品系统是稳定的。综上,关于稳定性的定义我们可以总结归纳为 -- 当系统接收输入后,能够产生正确的、符合预期的输出,称系统为稳定;否则,称系统为不稳定。 再回到命题上,为什么叫稳定性保障?能不能换一个说法叫提高稳定性?通过上文的定义我们可以总结出,稳定性描述的是系统的行为。一个系统是否稳定,就像我们评价一个人是否健康一样,很难用陈述的方式进行完整的描述,去量化。但是却可以通过否定的方式进行快速地判断。人们通过良好的饮食和生活习惯来减少疾病的发生,保持身体的健康。保障系统的稳定性或者说提高系统的稳定性也是如此,我们需要通过各种方法来避免那些不稳定的情况发生。所谓的更稳定,客观上并不存在,是主观上希望避免或者减少不稳定的情况发生。 与稳定性不同,可用性是一个可以量化的指标,计算的公式在维基百科中是这样描述的:
根据系统损害、无法使用的时间,以及由无法运作恢复到可运作状况的时间,与系统总运作时间的比较。
我们经常听到的3个9(99.9%),4个9(99.99%)度量的就是系统的可用性,高可用就是要保证系统的这个指标维持在一个高水平。在公式的定义描述中,将系统的运行时间分成了三个部分
- 系统正常运作的时间,即系统处于稳定状态的时间。
- 系统损害、无法使用的时间,即系统处于非稳定状态的时间。
- 系统由无法运作恢复到可运作状况的时间,即系统由非稳定状态恢复到稳定状态的时间。
系统的可用性和系统的稳定性是成正相关的。不过在现实生活中,系统是不可能永远处于稳定状态。逆向思考,将上述的公式进行转换,更有利于我们进行分析:

至此,本次命题的目标,KPI就清晰了。保障系统的稳定性和高可用的目标是使系统处于稳定的工作状态,对用户不产生负面的影响,避免线上问题和P级故障的发生。核心kpi是系统的可用性。为了提高系统的可用性,我们应该首先保障系统的稳定性,减少非稳定状况的发生,其次当系统由于各个组成部分发生故障,出现非稳定状态时,能够快速发现并将其恢复到稳定可用的状态。
二、 稳定性与高可用保障的核心思路
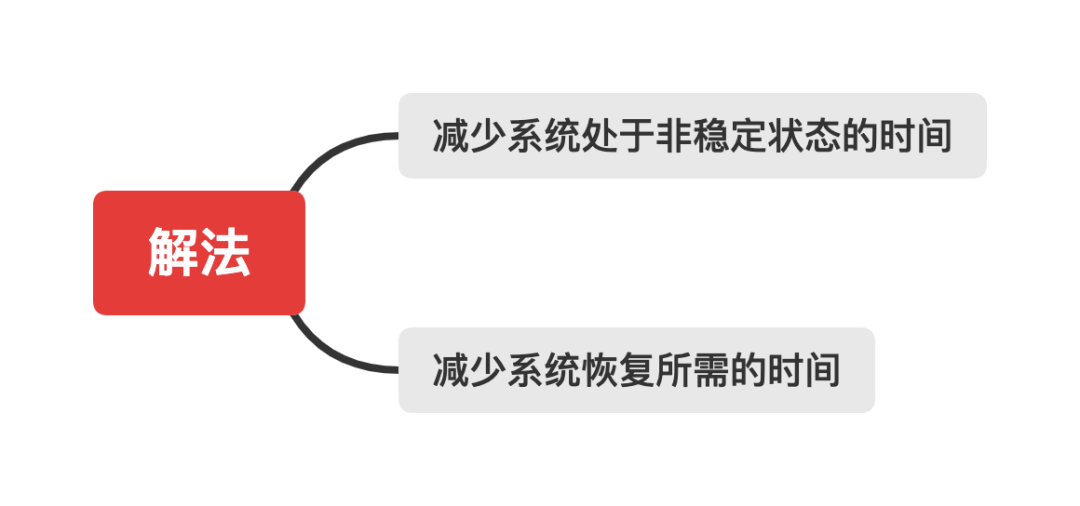
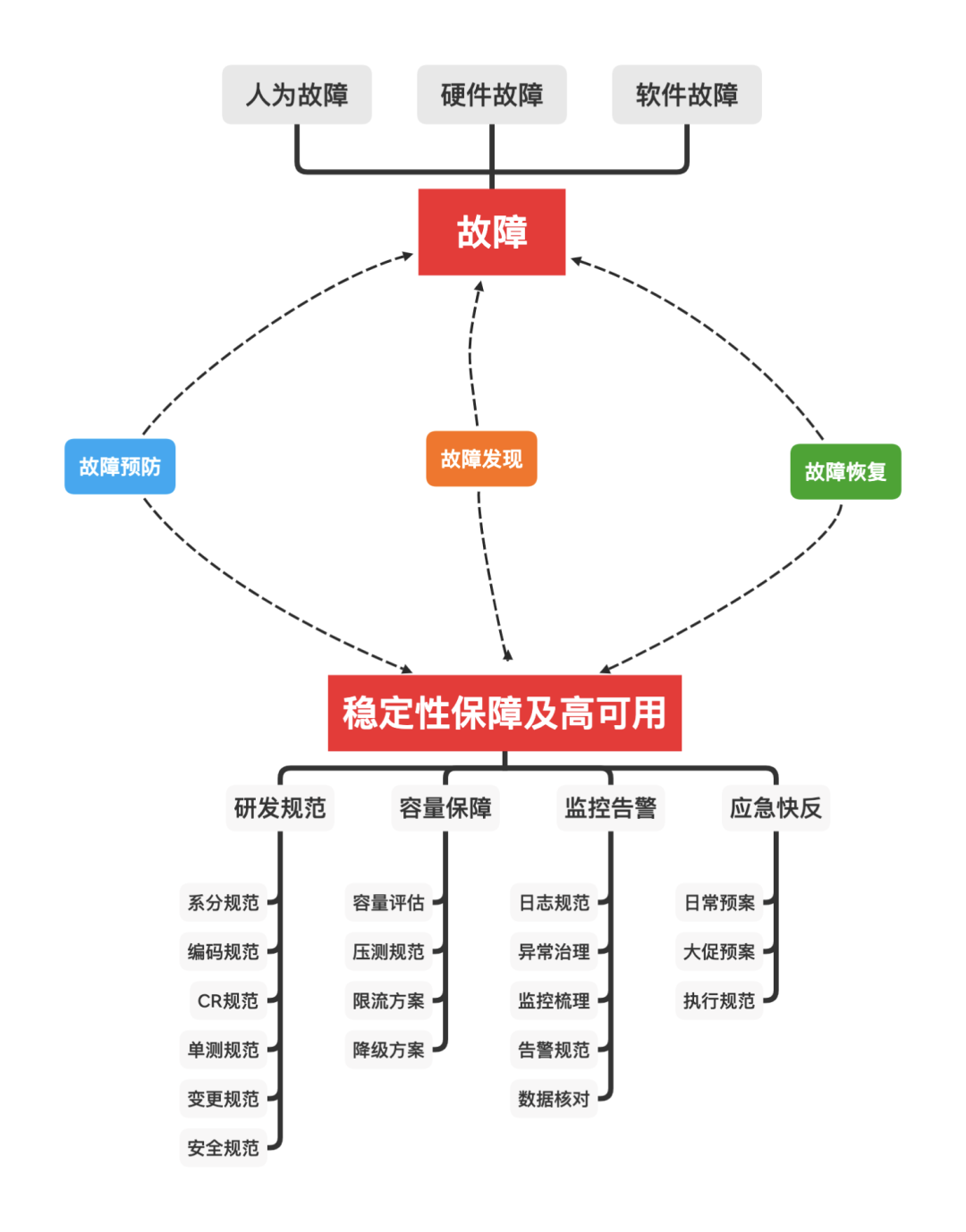
通过上文的推演,针对提高系统可用性这一目标,我们能够得到两个基本的解题思路。按图索骥,为了解决问题,首要的任务是发现和定义问题。因此为了提高系统的稳定性,我们先列举应用系统中常见的非稳定的情况,再一一对症下药:
- 功能:应用程序执行的功能出现错误,不符合预期。
- 容量:当系统接收的请求数量增加时,应用程序无法正常处理,出现异常或超时,导致服务失效。
- 安全:当系统接收到的没有授权的或者恶意攻击的请求时,应用程序出现异常甚至服务失效。
- 容错:对于用户错误的使用方式, 应用程序无法合适地处理。
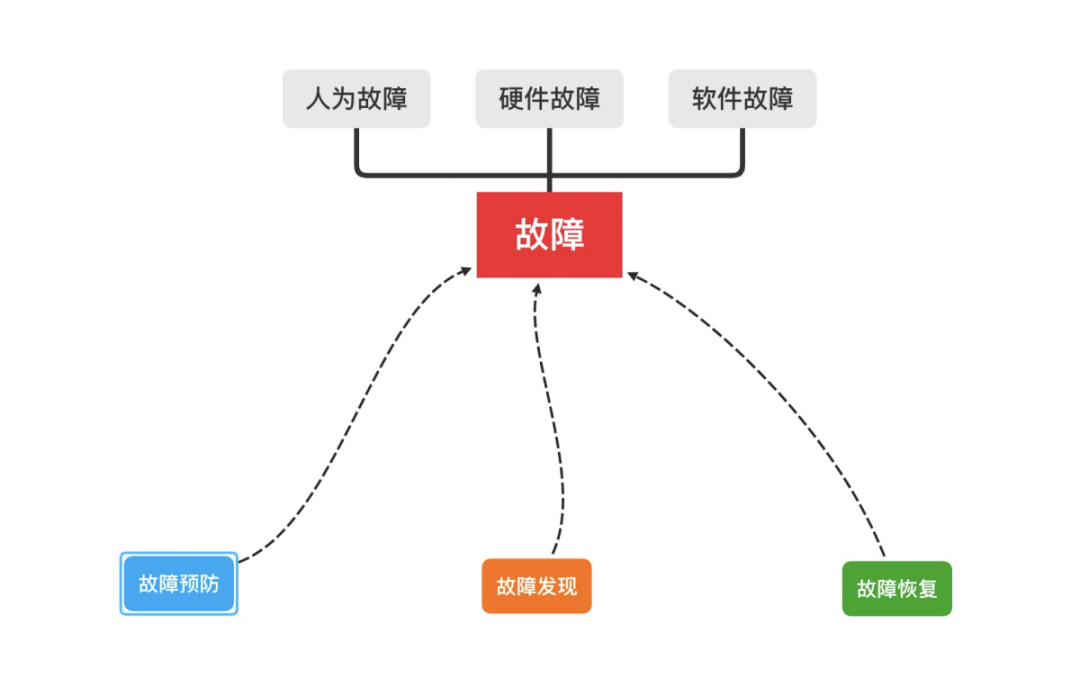
当上述情况发生时,就意味着系统处于不稳定的状态,需要我们能够及时发现并进行处理。而造成这些问题的原因,在软件系统中通常可以归结为以下三类:
- 人为故障:在开发软件的各个环节中思考不充分,或者执行时粗心导致的各类问题。
- 硬件故障:网络不通,硬盘空间不够,内存崩溃等。
- 软件故障:线程池异常,JVM异常,中间件或其他依赖的应用服务异常。
对于一个动态演进的系统而言,我们没有办法将故障发生的概率降为0,只能通过在软件生产的过程中,建立流程规范和机制来尽量减少其发生。其次对于一个运行的系统,我们需要建立并完善监控和预警机制来及时发现系统中的故障,并通过执行预案使系统快速恢复。基于上述结论,为了提高系统的可用性,需要从以下三个方面入手开展工作:故障预防,故障发现和故障恢复。
人犯错的几率是远远大于机器的,因此故障预防最重要的是建立一套机制,在团队内达成共识并持续按照此流程开展研发工作,从而减少个人因素(思考、执行、状态等方面)对系统稳定性的影响。而故障发现以及故障恢复,则是需要通过系统监控和应急方案来快速发现系统异常并恢复,从而尽量减轻故障的影响面。下面以蚂蚁日常的产品研发流程为例,从功能、容量、安全、容错这4个核心要素出发,给出一套方案仅供参考。
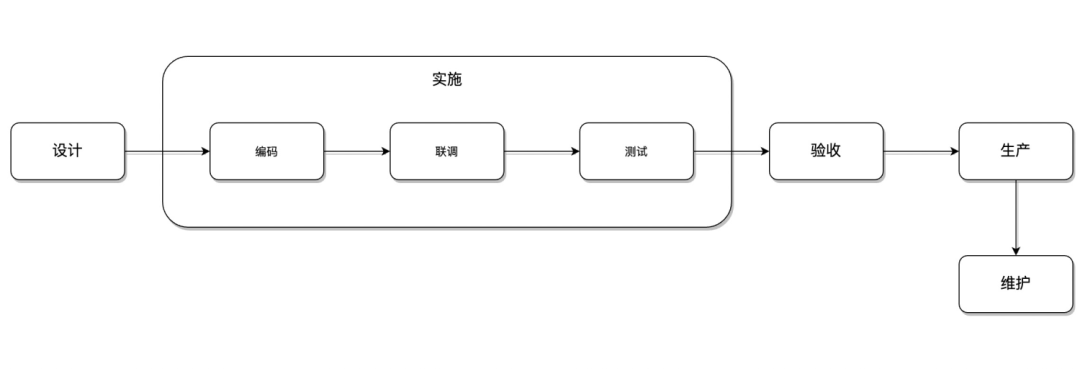
1. 研发规范
(1)设计阶段
1)团队细分文档模板
2)高可用设计规范
(2)编码阶段
1)代码规范
- 通用代码规范
- 工程结构规范
2)单测覆盖率
- 单测通过率
- 代码覆盖率
3)日志规范
4)安全漏洞修复规范
(3)发布阶段
(4)变更规范:三板斧
2.容量保障
(1)容量评估
1)机器容量
2)DB容量
3)缓存容量
(2)压测摸底
(3)限流方案
(4)降级方案
3. 监控告警
(1)日志规范
(2)监控梳理
1)应用基础监控
2)网关监控
3)服务监控
4)业务监控
5)限流监控
(3)告警规范
(4)数据核对
4. 应急快反
(1)日常预案
1)硬件异常预案
2)中间件异常预案
3)业务异常预案
(2)大促预案
(3)预案执行规范
三、总结
如何做好稳定性和高可用保障是一个很庞大的命题,其中的任一小部分内容在内网都可以搜到大量的文章。写这篇文章的目的是总结一下自己对稳定性和高可用保障工作的理解,给大家分享一套系统的框架思路。希望大家在读后能够更全面的了解安全生产,不陷于细节。