作者 | 汪阳
背景
自动化测试从最早期的录制回放技术开始,逐步发展成DOM对象识别与分层自动化,以及基于POM(Page Object
Model)来提高用例复用,到当前火热的基于AI技术的自动化,体现了自动化测试的发展趋势是更加智能,更加精准,更加高效。
在这里我们给大家介绍两种在业界已经有广泛使用的智能自动化测试技术:
- 自愈(Self-Healing)技术
- 机器学习(Machine Learning)技术

自愈技术
1. 什么是自愈技术
自愈(Self-Healing)技术在计算机术语中是指:一种自我修复的管理机制。
类比生命体,当生命体遭受到一些小的伤害时,它们的身体往往能够通过自身的修复机制来实现自愈,而不需要外界加以干预。如壁虎的断尾再生,或者蟹类的躯体再生能力那样。
回到计算机领域,自愈技术也在广泛地使用,比如芯片的信息通道自愈,软件系统的故障自愈等。那么我们这里要介绍的是在自动化测试方向上的一种自愈技术:
可以发现其测试脚本执行中的非预期错误,并在无需人工干预的情况下自行更改,从而将自身恢复到更好的运行状态。
2. 原理介绍
问题域:在自动化测试中使用自愈技术主要解决的是对象识别(object identification)问题。
传统的自动化测试框架和工具,使用应用程序模型来定义应用程序的组件和对象及其属性。然后使用这些定义来识别和操作应用程序组件。但是应用程序在更新时会经常更改。可能是有意的开发人员变更或者是即时(由应用程序系统或构建过程)发生的。这些变化破坏了我们基于静态定义的传统自动化方式。
自然语言处理(NLP)和机器学习 (ML) 等智能技术已经发展到测试脚本现在可以“学习”和“适应”的地步;自愈式自动化测试工具使用 AI 和机器学习技术,根据用户界面 (UI) 或应用程序环境的变化,可以自动更新和调整测试过程。
在运行测试时,它们会扫描应用程序的用户界面以查看是否存在任何对象。然后它们将这些对象与之前为自动化测试生成的应用程序模型进行比较。如果应用程序有任何更改,则有一种技术可以让测试适应并自动更新。这种能力被称为“自我修复”。属性更改是自动感知的,内部脚本在运行时通过自我修复进行自我修复。
自愈功能具有以下两个显著特点:
- 在执行过程中,如果某个测试步骤定位器无法被其默认定位器值检测到,则列表中的其他定位器策略将自动应用,无需测试人员的任何手动干预。执行将继续,就好像没有发生任何故障一样。
- 在执行过程中,如果测试步骤定位器失败,并且无法使用任何其他定位器策略自动检测到,测试将暂停执行,允许用户选择相关元素并继续执行。新的定位器策略将在下次执行时自动更新。
下图介绍了自愈技术的主要步骤:

(图片来源:https://www.impactqa.com/blog/5-great-ways-to-achieve-complete-automation-with-ai-and-ml/)
自动化测试自愈技术的优势主要有:
(1) 减少测试失败率
测试执行失败很正常,但是有时候失败的根本原因仅仅是由于用户界 面发生了变化而测试脚本没有同步变化。使用自愈技术后,由于无法正确识别的对象位置而影响脚本执行失败的情况就不太可能发生。而传统的自动化方式无法识别这些变化并自动更新。
(2) 提升测试稳定性
如果我们测试过程中有flaky tests存在的话,我们很难确定我们的测试是否是稳定的。”NoSuchElementException“ 错误是导致测试设计不稳定的几个错误之一,测试团队很难完全控制这样的现象发生。而当我们的测试设计和应用程序保持一致时,测试在执行期间失败的可能性较小,并且执行过程也更加顺畅。
(3) 提高脚本维护性
测试代码中的更改与开发人员在应用程序中所做的更改成正相关。由于测试失败的原因可能会发生变化,并且不能反映 AUT 的真实状态;因此失败的测试结果会限制测试人员获得有关其测试的有意义的见解。通过识别和更新用户界面中的任何更改的测试用例,自愈技术节省了敏捷测试和开发团队的时间和精力。除了时间和精力之外,测试自动化中的自我修复也显着降低了测试脚本维护成本。
3. 业内实践
我们可以看到,业内已经有一些比较好的实践了,比如Healenium项目。
以Healenium项目为例,看看自动化测试自愈技术是怎么工作的:
假设我们通过id 的方式来定位应用程序界面上的一个按钮,定位器应该是:#button
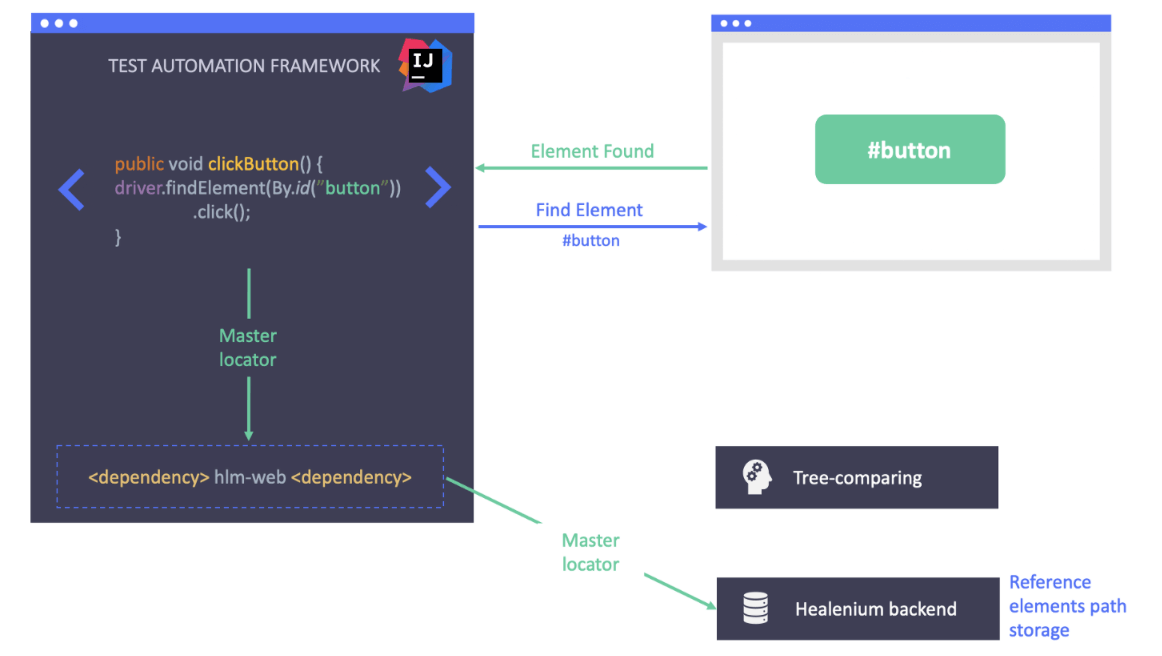

从上图可以看到,元素可以被正确定位到。Healnium会将正确的定位器保存下来,作为下一次测试执行的基准值。现在,我们假设开发人员变更了应用程序的UI界面,改变了这个按钮的id属性,从#button变更为#green_button。但是由于某种原因,测试团队没有被通知到有这个变更,所以测试脚本也没有更新。那么当我们再次执行脚本的时候,在尝试使用#button的旧定位器去定位按钮的时候,脚本就会报错,提示 “NoSuchElement”的错误异常。

在这种情况下,使用标准的 Selenium 实现测试将失败,但使用 Healenium 则不会。Healenium 捕获 NoSuchElement 异常,触发机器学习算法,传递当前页面状态,获取之前成功的定位器路径,比较它们,并生成修复的定位器列表。它采用得分最高的定位器并使用该定位器执行操作。正如我们看到的元素被成功找到并通过了测试。

测试运行后,Healenium 生成报告,其中包含有关修复定位器、屏幕截图和修复成功反馈按钮的所有详细信息。

如果修复成功,我们可以使用 Healenium Idea 插件更新我们的自动化测试代码:插件使用修复定位器寻找修复和更新测试代码。

Healenium 使用一种机器学习算法来分析当前网页的变化:基于权重的最长公共子序列算法.
更多关于这个项目的详情,可以访问这个项目官网:https://healenium.io/
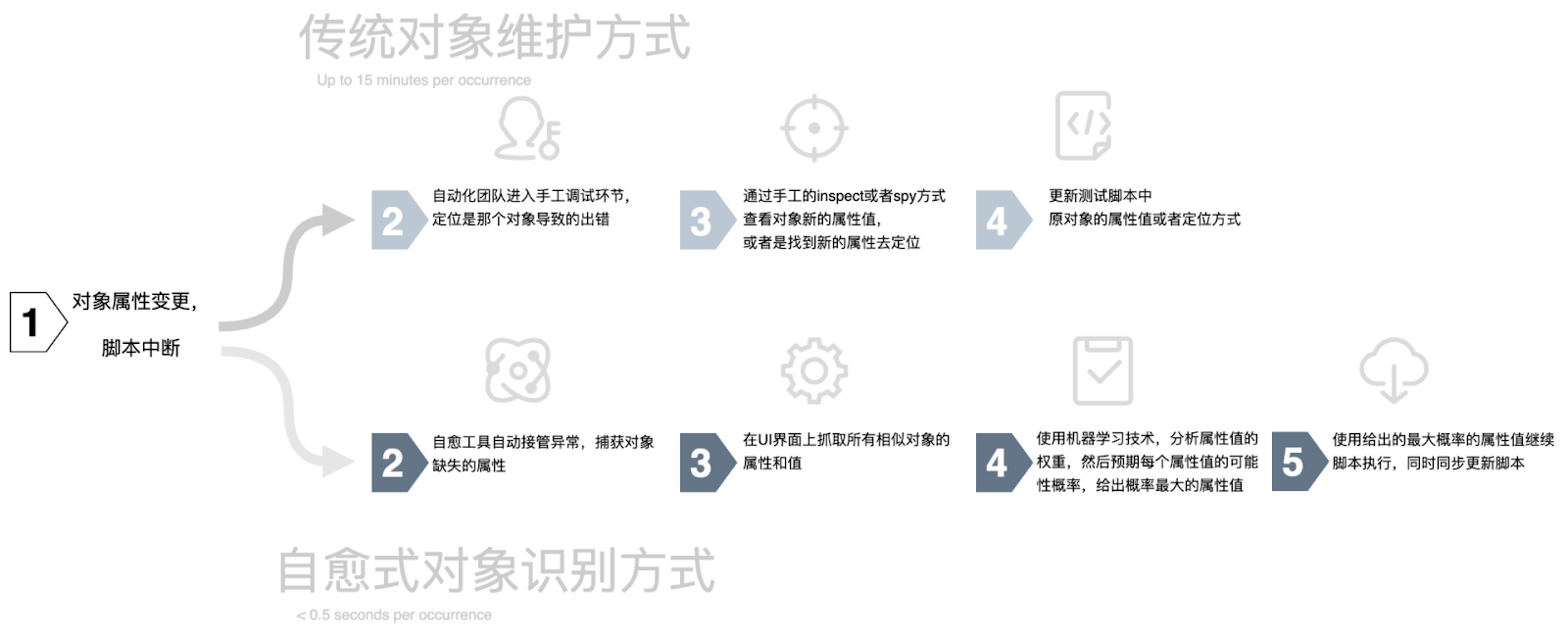
通过这个案例,我们来对比一下传统自动化测试方式和基于自愈技术的自动化测试方式中对象维护的差异(如下图所示):
二、机器学习
在上一部分,我们介绍了通过自愈技术解决自动化测试过程中对象识别问题。但是在自动化测试过程中,我们仍然还会面临其他问题:
- 仍然需要人工获取定位方式;
- 如果是通过Canvas绘制出来的对象,如何识别元素 (如Flutter Web)。
等等。
虽然自愈技术在传统的自动化测试中增加了一些容错能力。但是本质上还是基于元素定位的对象识别技术,用到的还是传统的DOM定位技术,如XPath或者是CSS定位器。
而我们知道,移动端和Web端的运行环境复杂,外部干扰因素很容易破坏自动化脚本运行的稳定性,这是元素定位器脆性本质导致的。
所以业界也一直在持续探索更稳定的对象识别技术。在早期我们使用到了CV(Computer Vision)计算机视觉 +OCR(Optical Character Recognition)光学字符设别技术。
而CV和OCR是基于图像处理和统计机器学习方法。
比如业内比较流行的自动化测试框架airtest,就是基于CV技术来进行智能控件识别的。
通过OCR及图像识别能力,实现相同流程下,一套自动化脚本可以在多平台上执行的能力,大大降低了脚本编写及后期维护成本。
目前业界也在实践与探索基于机器学习技术的CV和OCR来解决自动化测试学习成本高、维护成本高、Hybird识别差、跨应用能力差,以及不支持跨平台等方面的问题。
1. 智能识别
在UI页面中,我们的信息主要由图像和文字构成。如何高效地识别基于图像和文字的控件对象,是当前自动化测试不得不面临的问题。为了解决之前基于DOM技术的元素定位不稳定,以及后期的维护成本。目前在UI控件识别上有两种方式:一个是基于CV技术的图像识别,一个是基于OCR技术的文字识别。
(1) 基于CV的图像识别
a. 传统的CV
在传统方式下,我们主要是基于图像特征识别技术:
提到图像识别算法一定绕不开OpenCV,常用的是SIFT算法,核心就是提取出图片当中的一些关键特征,这些特征在不同的机型,在不同的分辨率下面有很好的适应性。基于传统特征识别技术的处理过程如下图所示:

b. 基于深度学习的CV
这种方法比现行的定位策略( image )更灵活,因为我们可以用CNN,或者其他深度学习框架来训练 AI 模型去识别控件图标,并不需要知道上下文,也不需要精确匹配控件图标。也就是说我们可以能跨应用和平台去找一个如 “购物车” 的图标这样的控件,不需要在意一些细微的差别。基于深度学习的处理流程如下图所示:

尽管基于深度学习的CV具有更强的能力,但是传统的方式依然有不可替代的优势,值得我们继续学习。如从目前来看深度学习仍然需要大量的数据,而传统的方式在这方面就会节省很大的成本。对于一些比较简单的识别任务,我们更推荐传统的CV方式。
(2) 基于OCR文字识别
OCR可识别屏幕上的预定义字符。使用OCR的软件将采用“最佳猜测”的方式来确定图像是否与字符匹配,以便将该图像转换为计算机可以处理的文本。传统的OCR基于图像处理(二值化、连通域分析、投影分析等)和统计机器学习(Adaboost、SVM)。
传统的OCR只能处理相对简单的场景,如:简单的页面布局、前景和背景信息便于区分及每个文本字符容易分割。随着我们的测试对象月来越复杂,页面布局,样式等多样化的场景下,传统OCR的精准度也受到了挑战。
随着深度学习的发展,我们可以通过新的算法技术来解决传统OCR的局限性。
2. 案例实践
在业内,大部分基于AI的自动化测试平台均采用了CV+OCR结合的智能识别技术,来降低自动化测试脚本编写成本以及后期的维护成本。我们分别以基于OpenCV的airtest 平台为例:基于OpenCV的UI自动化 - AirtestAirtest主要用到了两种传统的OpenCV匹配算法:模版匹配和特征匹配。
模板匹配:
- 无法跨分辨率识别
- 一定有相对最佳的匹配结果
- 方法名:"tpl", "mstpl"
特征点匹配:
- 跨分辨率识别
- 不一定有匹配结果
- 方法名列表:["kaze", "brisk", "akaze", "orb", "sift", "surf", "brief"]
在Airtest中可以自己配置选择使用的匹配算法。由于两种匹配算法各有利弊,因此一般默认是选择这几种匹配算法组合,算法依次进行图像识别,找到结果将停止识别,未找到结果将会一直按照这个算法的识别顺序一直循环识别直到超时。
如何判断图像识别成功或者失败呢?Airtest里面有两个重要的名词:阀值和可信度,阀值是可以配置的,一般默认为0.7,可信度是算法执行结束后计算出来的可能性概率,当 可信度>阙值 的时候,程序会认为 找到了最佳的匹配结果 ;而当 可信度<阙值 的时候,程序则会认为 没有找到最佳的匹配结果 。
如下这个例子:在Airtest中操作网易云音乐APP :

Touch(“图片”) 的原理如下:

Airtest本身并没有直接提供OCR方式识别,不过我们可以通过集成开源的Tesseract-OCR库来支持OCR识别能力。
面临的挑战:
基于传统的OpenCV的图像识别,主要的问题是图像的特征识别不够准确,特别是在图像本身的特征比较少,如有一大片白色背景等,或者是动态元素等。同时传统的识别成功率平均也就80%左右,还达不到人工的95%的准确率,因此在传统方式下,我们只能通过添加更多特征信息来优化识别率,但是想要匹配人工的准确率,传统的统计机器学习方式很难达到。
解决这个问题就需要更强的泛化能力,目前更多的是基于CNN等深度学习技术来解决此类问题。我们这里就不过多展开,大家可以参考Appium with AI项目。
详情:https://appiumpro.com/editions/39-early-stage-ai-for-appium-test-automation
3. 未来展望
随着DL,RL和NLP等技术的不断发展,未来是不是完全可以将我们的用户故事自动转化为自动化测试用例,做到了真正的零代码呢,目前业内也有这样的探索了,我们也在持续跟进。
CV和AI算法的加持让UI自动化测试在对象识别上有了新的突破,但依然无法摆脱软件层API操作的局限,受所在操作系统限制,依旧存在部分特定场景下元素无法识别的问题(如系统内Push消息操作)。
我们可以看到业内领先的公司在尝试自动机械臂方式,来解决这个问题。
如下图阿里的Robot-XT:

(图片出处:https://mp.weixin.qq.com/s/5ZngQyJiRZy6714-CC498g)
那么这些技术是否是大厂的“专利”呢? 我想答案是否定的,未来AI技术一定也会像水电煤一样,变成最基础的底层设施,我们只需要会用即可。
三、总结
在本文中,我们介绍了两种应用比较广泛的自动化测试新技术,目的是帮助大家了解自动化测试未来的发展趋势,从而更好地利用新技术来提高我们的测试效率。
自动化测试未来趋势不仅仅是这两种,还有如智能化探索性测试,智能遍历测试以及智能验证等。

