介绍
许多机器学习问题依赖大量的数据进行训练,然后进行推理。大型互联网规模的公司用tb或pb的数据进行训练,并从中创建模型。这些模型由权重组成,这些权重将优化大多数情况下的推理误差。权重/参数的数量以数十亿至数万亿的顺序排列。在这样大的模型中,在一台机器上学习和推理都是不可能的。有一个可以用于分布式学习和推理的框架是很有用的。由于参数需要在多个节点之间共享,然后使用这些节点执行和完善它们的计算来更新它们,所以当涉及到共享时,这些大量数据可能成为瓶颈。共享在带宽、顺序机器学习(ML)算法的同步、机器的容错性方面代价高昂,故障率高达10%。Parameter sever(https://www.cs.cmu.edu/~muli/file/parameter_server_osdi14.pdf)提出了一种新的框架来解决这些问题,并构建了分布式机器学习算法。

主要设计理念
Parameter Server提出了以下设计要求:
- 高效通信:一种异步任务模型和API,可以减少机器学习(ML)算法的整体网络带宽
- 灵活的一致性模型:宽松的一致性有助于降低同步成本。它还允许开发人员在算法收敛和系统性能之间进行选择。
- 添加资源的弹性:允许添加更多容量而无需重新启动整个计算。
- 高效的容错:在高故障率和大量数据的情况下,如果机器故障不是灾难性的,可以在一秒钟左右的时间内快速恢复任务。
- 易用性:构造API以支持ML构造,例如稀疏向量,矩阵或张量。
分布式机器学习算法的示例
经典的监督机器学习(ML)问题包括在给定标记数据的训练集的情况下优化成本函数。在许多样本上改变和调整成本函数,以减少或最小化预测误差。为了调整模型或减少误差,计算偏导数/梯度。这些梯度有助于在正确的方向上移动权重,以最大限度地减少误差。
对于“d”维特征向量,模型尝试使用以下公式预测先前未见过的x的结果:for every i=1 to d, ∑xi * wi。为了确保模型相对较好地推广(即,它仅在训练数据上不能很好地执行),将正则化分量添加到预测函数。所以上面提到的函数变成Σxi* wi +ƛ* Norm(w)。这里ƛ用于惩罚在训练数据上发现的权重。这削弱了学习的权重,因此避免了过度拟合,并有助于对以前看不见的数据进行泛化。本文更侧重于该框架的系统方面。
让我们看看分布式随机梯度下降如何用于求解上述预测算法。下图描绘了迭代算法并行化工作的高级过程:
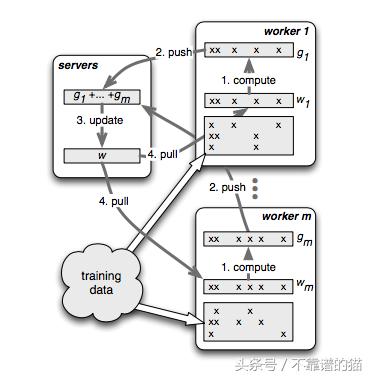
分布式训练算法
该系统由一些服务器节点和工作节点组成。每个worker加载一些数据子集,不同的workers加载不同的样本。每个worker计算本地数据的梯度以优化损失函数。然后,每个worker将这些部分梯度发送到服务器节点。服务器节点聚合从许多worker是、节点接收的那些梯度。完成服务器节点后,worker节点可以从服务器节点提取新的权重集,并再次执行梯度计算。大多数时间花在计算g1,g2,...,gm梯度上。这些是使用转置(X)* w计算的。如果w的数量级为数十亿至数万亿,这种计算在任何单个节点上都是不可行的。但是,每个节点仅处理数据子集的良好副作用是,他们只需要相对应的权重,如数据。如果一个人试图预测可能是用户点击一个广告,然后“regularizers”等词语不太有趣,大多数workers不会更新权重。正如你所看到的在上面的图中,给定节点上,只有x的权重(w)的特征存在/相关的点积是必要发送给工人节点(参见x在每个工作节点和相应的列稀疏权向量w)。
在较高的层次上,算法在每个worker上看起来如下:
- 在每个worker上,计算数据子集的梯度(偏导数)
- 将此部分梯度推送到服务器
- 在服务器准备就绪时从服务器中提取新的权重集
在每台服务器上:
- 汇总所有'm'个worker的梯度,例如g =Σgi
- new_weights = old_weights - learning_rate *(g +ƛ* Norm(old_weights))
架构
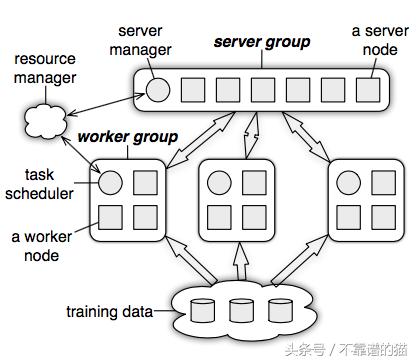
High level architecture
ParameterServer由服务器组组成,便于在系统中运行多种算法。服务器组中的每个服务器节点负责密钥空间/数据的分区。服务器可以相互通信以迁移/复制数据,以实现可伸缩性和可用性。服务器管理器负责维护服务器组的一致视图。它执行活动检查并为每个服务器节点分配密钥空间的所有权。
通常为应用程序分配工作组。多个workers节点构成工作组,它们与服务器组通信以提取参数和推送梯度,如上一节所述。工作组不需要相互通信。调度程序查看工作组并为其分配任务。通常,相同的工作节点通过在同一数据集上运行迭代算法来利用本地存储的数据。参数名称空间可用于在多个工作组之间进一步并行化工作。此外,可以在多个组之间共享相同的参数命名空间:典型示例是支持实时推理的一个组,而其他工作组可以支持模型的开发和共享参数的更新。
让我们看一下构建这种架构所需的一些原语
键值API
撰写本文时,现有系统使用键值对来传递共享参数。一个例子是feature-id及其权重。传统上,这是使用memcached或其他一些键值存储实现的。重要的见解是值主要是一些线性代数基元,例如向量或矩阵,并且能够优化对这些构造的操作是有用的。典型的操作是点积,矩阵乘法,L-2范数等。因此,保持键值语义和赋值作为向量,矩阵对于优化大多数常见的机器学习(ML)操作非常有用。
Range based push and pull
如前面算法中所述,从服务器节点和梯度中提取的权重被推送到服务器节点。支持基于Range的推送和拉取将优化网络带宽使用。因此,系统支持w.push(R,destination),w.pull(R,destination)来提取数据。在这两种情况下,对应于Range R中的键的值被从目的节点推送和拉出。将R设置为单个键,提供简单的键值读写语义。由于梯度g与w具有相同的密钥,因此w.push(R,g,destination)可用于将局部梯度推送到目的地。
异步任务和依赖
任务可以看作是rpc。任何push或pull请求都可以是任务,也可以是正在执行的远程函数。任务通常是异步的,程序/应用程序可以在发出任务后继续执行。一旦接收到(键、值)对中的响应,就可以将任务标记为已完成。只有当给定任务所依赖的所有子任务返回时,才能将任务标记为已完成。任务依赖有助于实现应用程序的总体控制流。
灵活的一致性模型
从上面的模型中可以看出,任务是并行运行的,通常在远程节点上运行。因此,在各种任务之间存在数据依赖关系的情况下,可能最终会拉出旧版本的数据。在机器学习中,有时用旧的或不太旧的权重,而不是最近的权重,并不是太有害。Parameterserver允许实现者选择它们所追求的一致性模型。如下图所示,支持三种类型的一致性模型。在顺序一致性中,所有任务都是一个接一个地执行。在最终的一致性中,所有的任务都是并行开始并最终聚合的。在有界延迟中,只要任何任务开始大于“t”次已经完成,任务就会启动 - 下面的图c显示有界延迟为1。
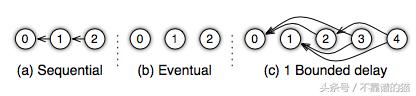
一致性模型
实施细节
向量时钟: 对于容错和恢复,系统中需要一些时间戳。Parameterserver使用向量时钟来建立系统中的某些事件顺序。基于节点数(m)和参数数量(p)即O(m * p),向量时钟可能很昂贵。考虑到系统中的大量参数,这可能非常大。由于大多数操作可以使用ranges完成,因此可以为每个range分配一个向量时钟,而不是每个range获得一个。如果系统中存在唯一的range,则通过该机制可以进一步降低复杂性,即O(m * r)。系统最初仅以m个时钟开始,因此属于该节点的整个密钥空间具有一个向量时钟。这可能会减慢恢复过程。因此,当在系统中创建更多ranges时,将更新的向量时钟分配给这些ranges分区。
消息:系统中的消息表示为(VectorClock(R),R中的所有键和值)。由于数据密集型机器学习(ML)应用程序中的通信量很大,因此可以通过高速缓存来减少带宽。在迭代算法中多次传递相同的密钥,因此节点可以缓存密钥。在迭代期间,这些值也可能包含许多未更改的值,因此可以有效地压缩。ParameterServer使用snappy compression 来有效地压缩大量零。
一致哈希:一致哈希用于轻松添加和删除系统的新节点。散列环上的每个服务器节点都负责一些密钥空间。密钥空间的分区和所有权由服务器管理器管理。
复制: 复制是由相邻节点完成的。每个节点复制它的k个相邻节点的键空间。负责密钥空间的主服务器通过同步通信与neighbors保持协调,以保持副本。每当master拉key ranges时,它将被复制到它的neighbors。当worker将数据推送到服务器时,在数据复制到从服务器之前,任务不会被确认为已完成。很明显,如果每次推和拉的时候都这样做的话,就会变得很繁琐。因此,系统还允许在聚合一定数量的数据之后进行复制。这个聚合如下图所示。s1和s2之间只交换一条复制消息。它是在x和y都被推送到S1之后,然后是S1上的函数计算任务,然后是复制的最后一条消息,随后确认(4,5a, 5b)流回worker1和worker2以完成任务。
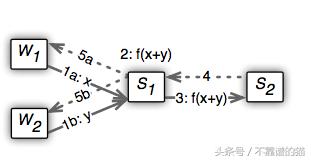
聚合后复制
- 服务器节点管理: 能够通过向系统添加新服务器节点进行扩展是有用的。发生这种情况时,服务器管理器会为新节点分配一个键空间。此键可以来自之前终止的某个节点,或者通过拆分负载很重的服务器节点的键空间。然后,这个新节点拉出它负责的密钥空间,并从k个neighbors中抽取副本作为从属。通常,可能需要两阶段提取来提取在被这个新节点提取时被覆盖的数据。然后,服务器管理器将此所有权分配消息广播到环上的其他节点,然后这些其他服务器节点可以根据此新的所有权分配缩小其密钥空间使用量。对于离开的节点,服务器管理器将密钥空间分配给某个新的传入节点。服务器管理器通过心跳维护节点运行状况。
- worler节点:添加新的工作节点相对简单。任务调度程序将数据范围分配给工作节点。这个新节点将从NFS或其他一些workers中提取数据。然后,调度程序将此消息广播给其他workers,以便其他workers可以通过放弃一些训练数据来回收一些空间。当工作节点离开时,它将由算法的所有者决定是否恢复数据 - 取决于数据的大小。
结论
本文阐述了分布式机器学习的一些重要概念。从系统的角度来看,本文结合使用了一些很好的技术,比如一致哈希。基于范围的通信和支持消息传递的本机机器学习(ML)构造似乎是构建高效机器学习(ML)框架的良好洞察力。

